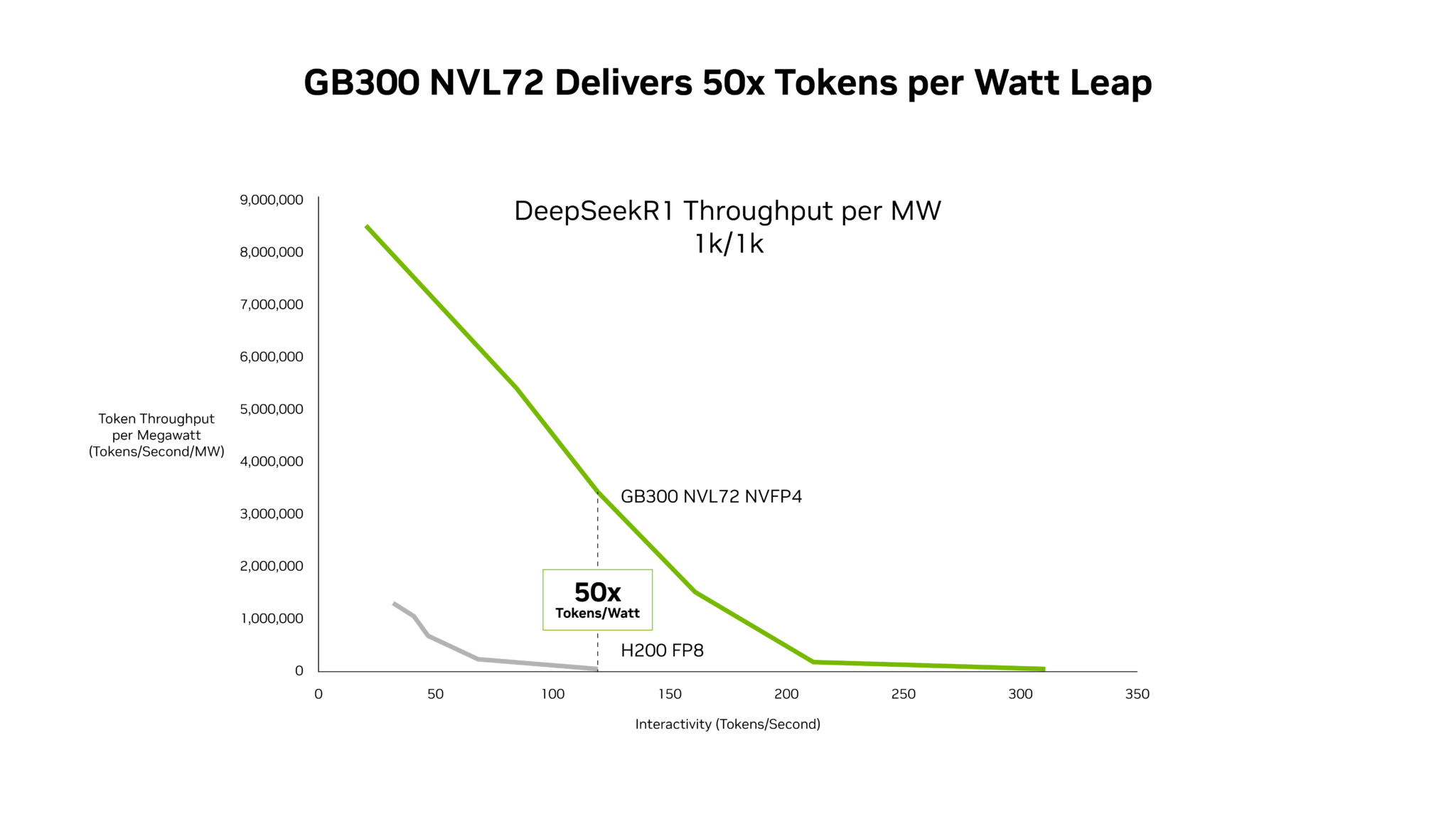
Con la progressiva adozione dell'IA da parte delle aziende, NVIDIA ritiene che il parametro più importante non sia più rappresentato esclusivamente dalla potenza teorica delle GPU, bensì dall'efficienza economica dell'inferenza. L'indicatore di riferimento diventa quindi il costo per token, ovvero il numero di token elaborati per dollaro/euro investito, per watt consumato e nel rispetto dei requisiti di latenza richiesti dalle applicazioni.
Secondo NVIDIA, il risultato dipende sempre più dal software che affianca l'hardware. L'azienda sostiene che il proprio stack completo di inferenza, sviluppato insieme alle GPU, CPU, reti NVLink e sistemi Blackwell, abbia già permesso di ridurre fino a cinque volte il costo per token del modello DeepSeek V4 nell'arco di circa un mese grazie a continui aggiornamenti software, senza modifiche dell'infrastruttura fisica.
Clicca per ingrandire
NVIDIA evidenzia come le moderne applicazioni di AI agentica siano molto diverse dai tradizionali servizi web. Se questi ultimi eseguivano richieste relativamente prevedibili verso database e servizi backend, i nuovi agenti AI possono orchestrare contemporaneamente modelli linguistici, strumenti esterni, memoria, componenti di sicurezza e numerosi sottoprocessi distribuiti.