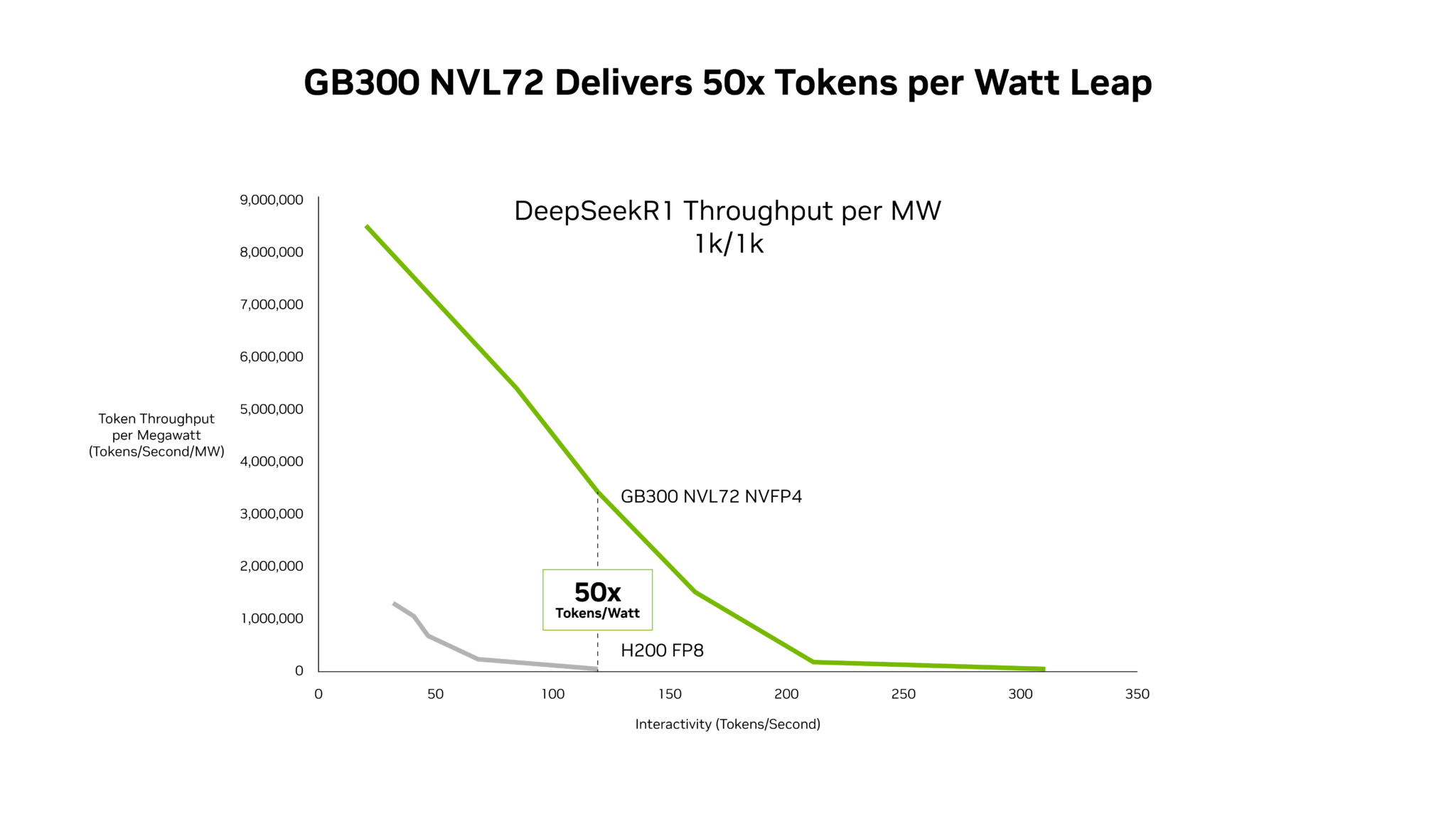
As organizations move from AI pilots to production AI factories, infrastructure decisions have shifted from peak chip specifications to cost per token: how many useful tokens they can deliver per dollar, per watt and within required latency targets.
Codesigned with NVIDIA GPUs, CPUs, networking and systems, and strengthened by a broad open source ecosystem, NVIDIA’s full-stack inference software continuously improves hardware performance. On the NVIDIA Blackwell platform, the software stack has already reduced token costs by up to 5x on the DeepSeek V4 model in just one month.
SemiAnalysis InferenceX results comparing token cost and interactivity for NVIDIA GB300 NVL72 systems with SGLang and the NVIDIA Dynamo inference framework.
Leading companies and inference providers are already seeing the compounding value of NVIDIA’s inference software stack on Blackwell:
Baseten used the NVIDIA TensorRT-LLM open source library to serve DeepSeek V4 Pro on Blackwell GPUs for reasoning, coding and long-context workloads, applying proprietary runtime optimizations to deliver up to 50% more tokens per second.