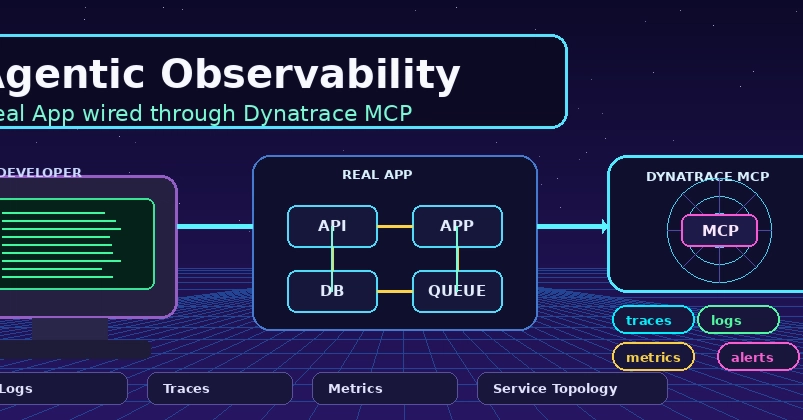
Modern DevOps teams are under pressure to detect failures earlier, reduce noisy alerts, and prove reliability without adding more manual work. That is why synthetic monitoring is becoming one of the most practical components of the observability stack: it provides a repeatable way to test critical user journeys, APIs, and third-party dependencies before customers experience the impact.
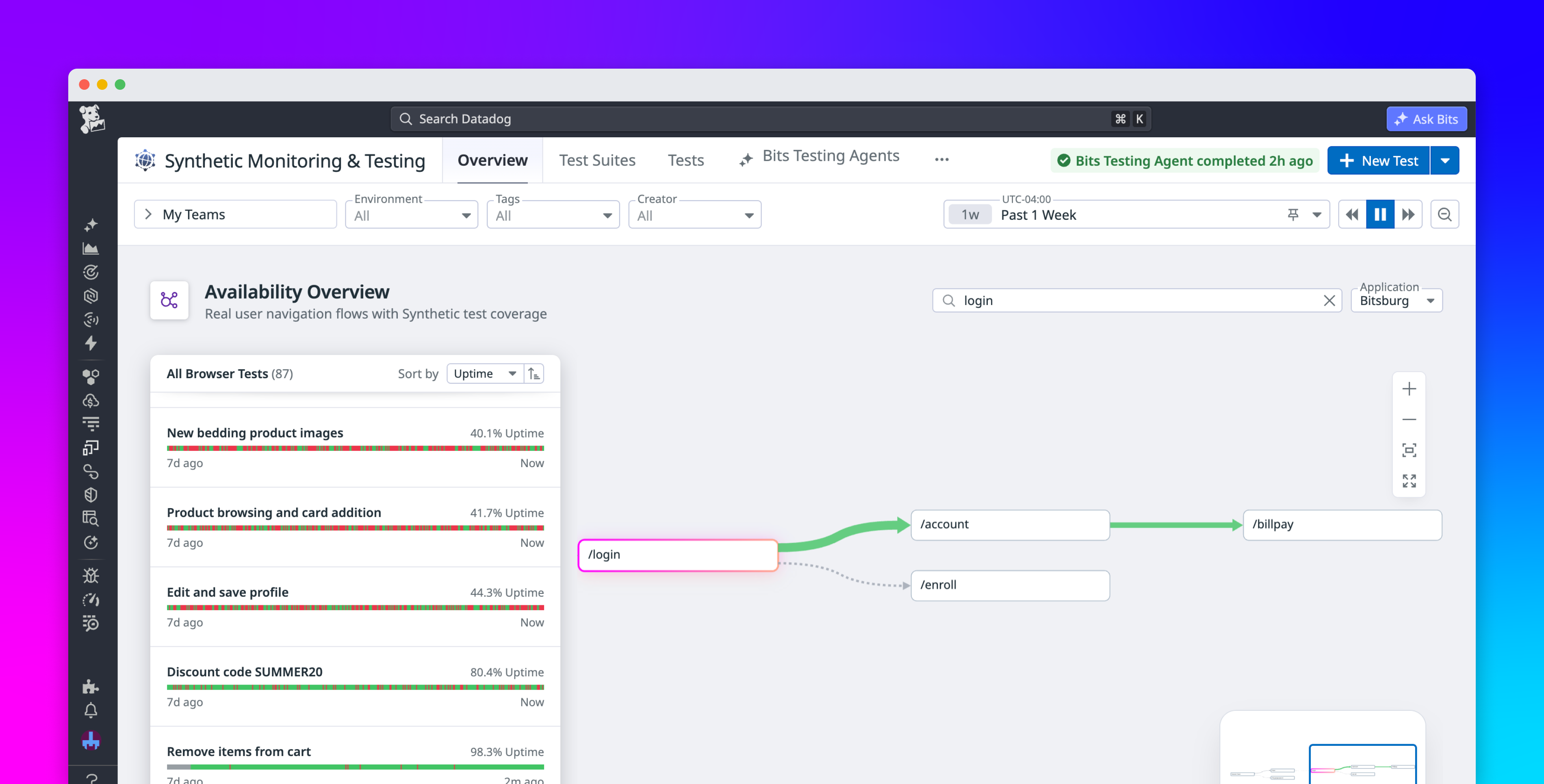
Synthetic monitoring is no longer a theoretical topic. It is now a hands-on reliability tool for teams that need to catch login failures, payment breakage, checkout slowness, webhook outages, DNS issues, and region-specific degradations long before a customer opens a ticket. In practice, the teams getting value from it are not just “watching uptime”; they are turning synthetic tests into an operational contract for their most important paths. witanworld
Why synthetic monitoring matters now
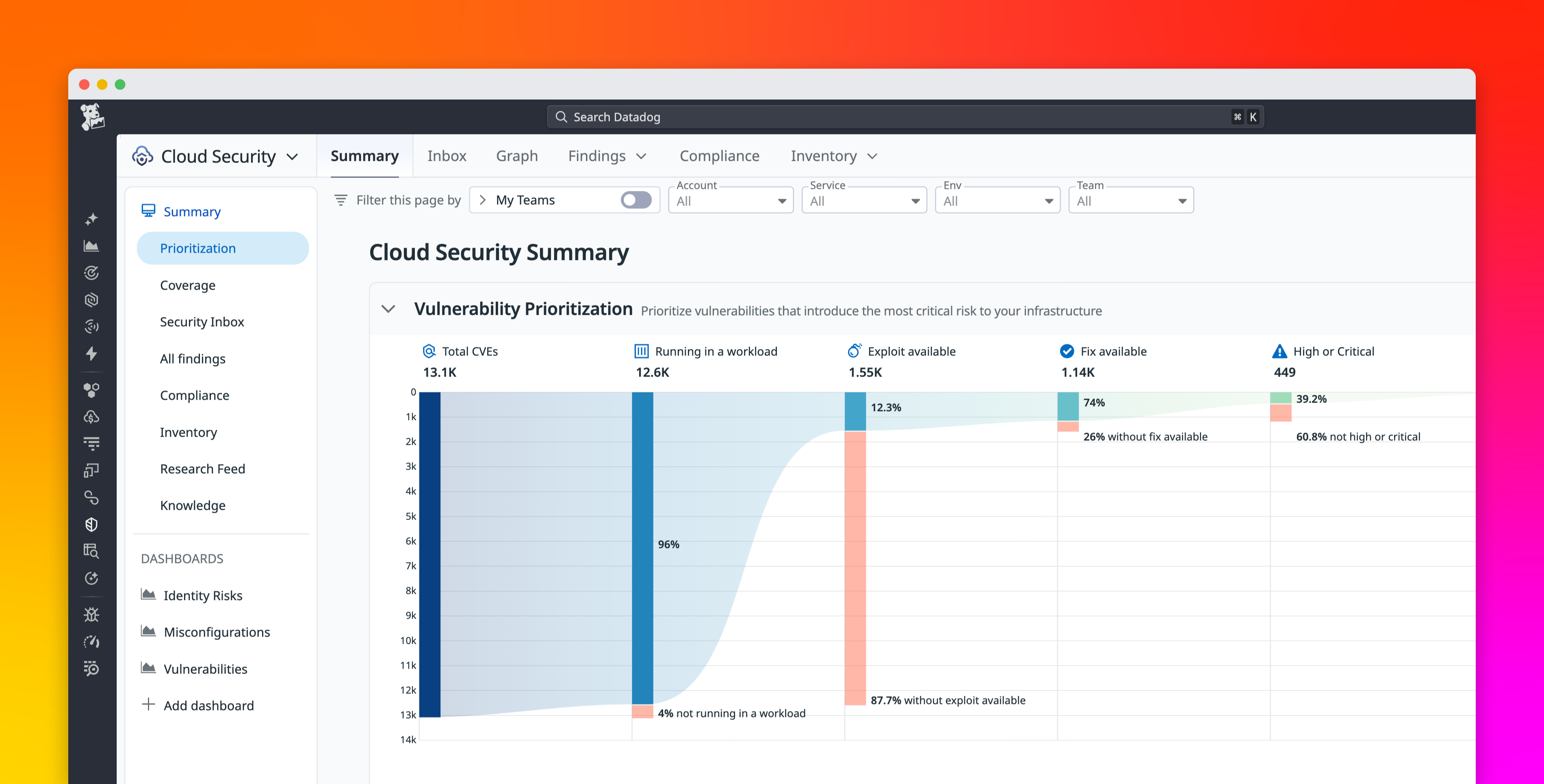
The biggest shift in modern ops is that services are no longer judged only by server health. A service can have green CPU graphs and still fail at the point that matters: authentication, external API calls, queued jobs, or browser-side rendering. That gap is exactly where synthetic monitoring helps, because it tests the experience the way a user or client actually consumes it.