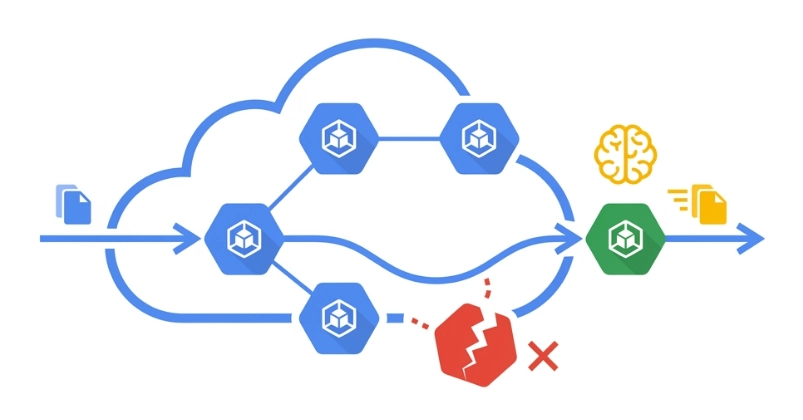
It's Tuesday morning. The platform team starts draining nodes for a Kubernetes upgrade. Sixty seconds later, Slack explodes — the payment service is fully down. All 3 replicas landed on the same two nodes, both drained simultaneously. There was nothing wrong with the app. The cluster did exactly what it was told.*
This is what PodDisruptionBudgets prevent.
The Problem
Kubernetes has two kinds of pod disruptions:
Involuntary: Node crashes, OOM kills, hardware failures. Unpredictable. You handle these with replicas and health checks.