You did everything right. You containerized your massive model training job, deployed it to Google Kubernetes Engine (GKE), and cleverly routed it to a Spot VM node pool to save up to 90% on compute costs.
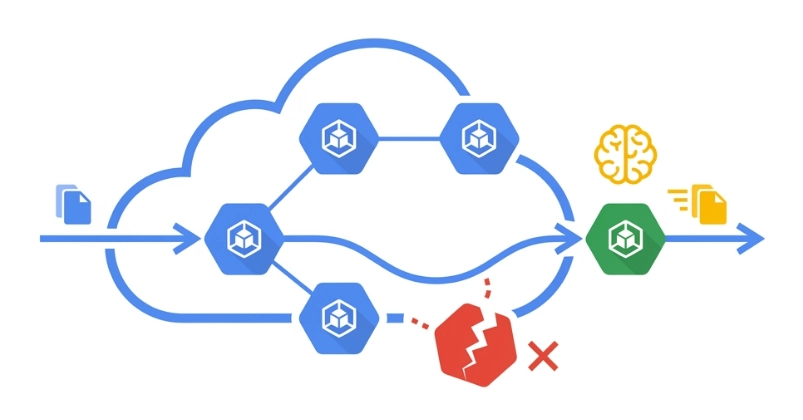
Everything is humming along perfectly for 38 hours. Then, a priority on-demand customer needs capacity, Google Cloud reclaims your underlying Spot VM, and your node vanishes.
Whether you are using preemptible Spot VMs to save money, or leveraging the Dynamic Workload Scheduler (DWS) to queue for scarce GPUs, you are building on top of ephemeral compute. The hardware will eventually be taken away. To successfully run critical AI workloads on un-committed capacity, your application architecture must assume failure is a given.
Here is a practical guide to building interruptible workloads on GKE.
1. Trap the warning