Right-sizing Kubernetes workloads is a common platform engineering challenge. Set your requests too high, and you burn cloud budgets on idle capacity; set your limits too low, and your applications face throttling or dreaded OOMKills.
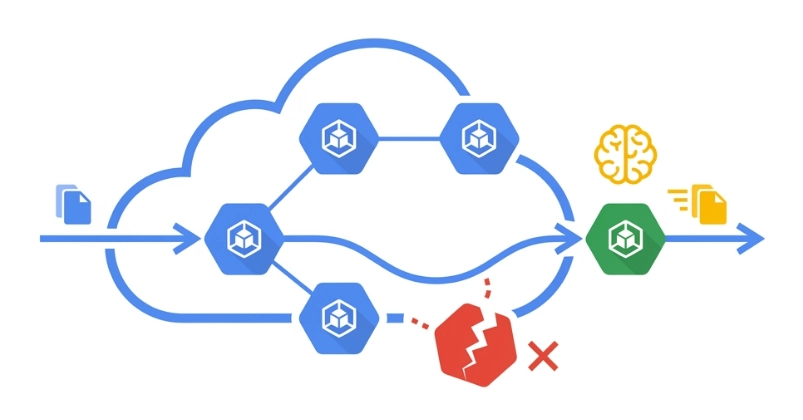
For years, the Vertical Pod Autoscaler (VPA) has been the standard answer to this problem, automatically adjusting CPU and memory requirements based on actual usage. However, this method of scaling came with a significant catch that prevented widespread adoption for critical workloads: applying new resource parameters required evicting and restarting the pod.
This disruption was often unacceptable for stateful applications, long-running connections, or latency-sensitive services.
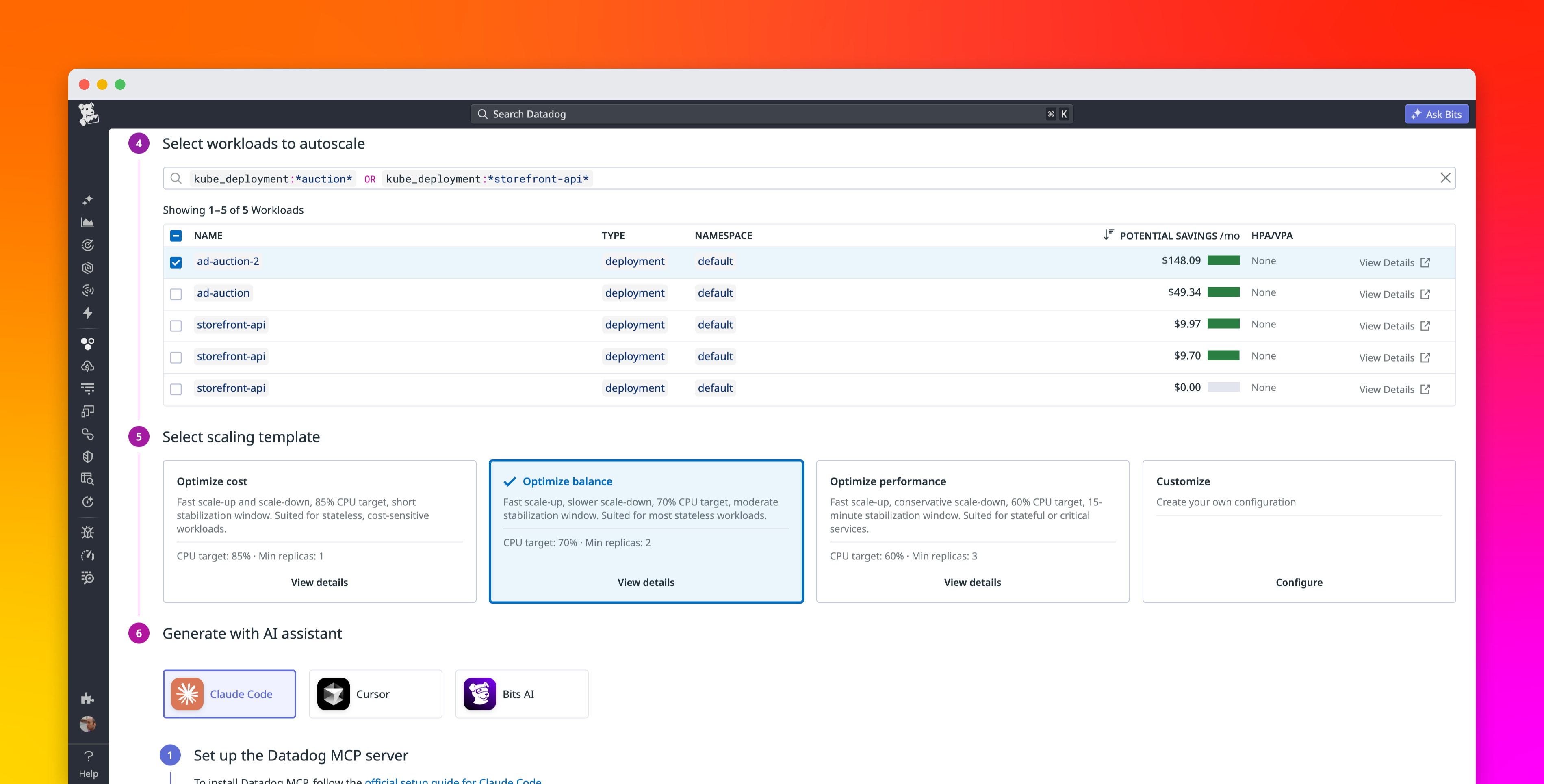
Introducing In-place Pod Resize (IPPR) on GKE
In-place Pod Resize (IPPR) changes the game by allowing Kubernetes to modify resource requests and limits on live, running containers directly through the underlying container runtime, without triggering a restart.