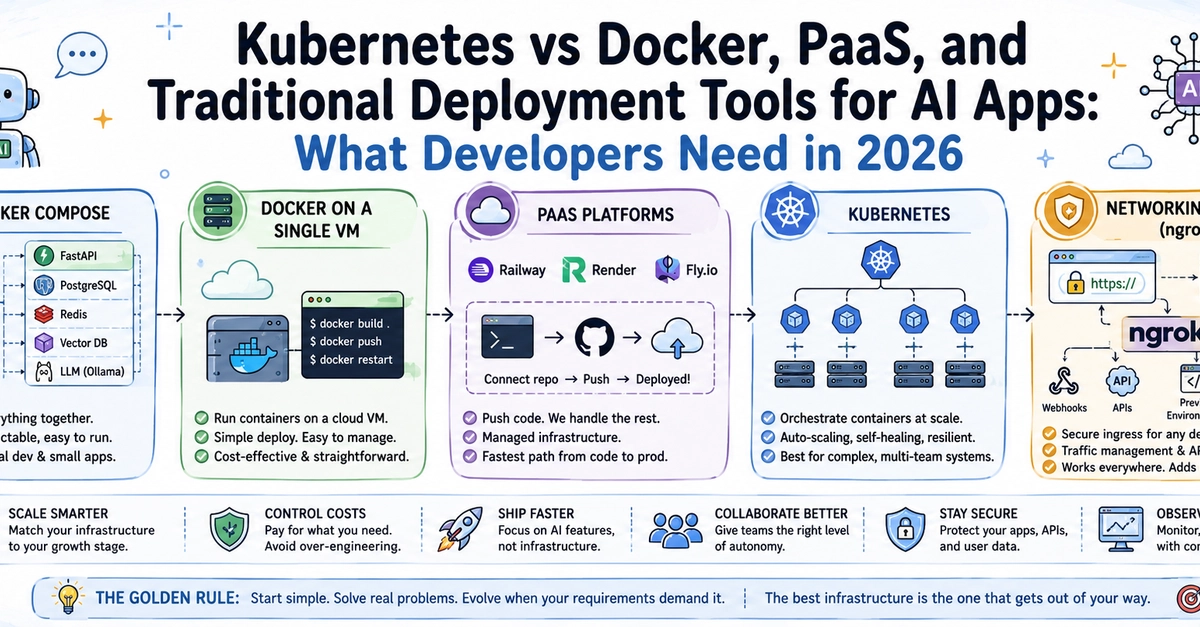
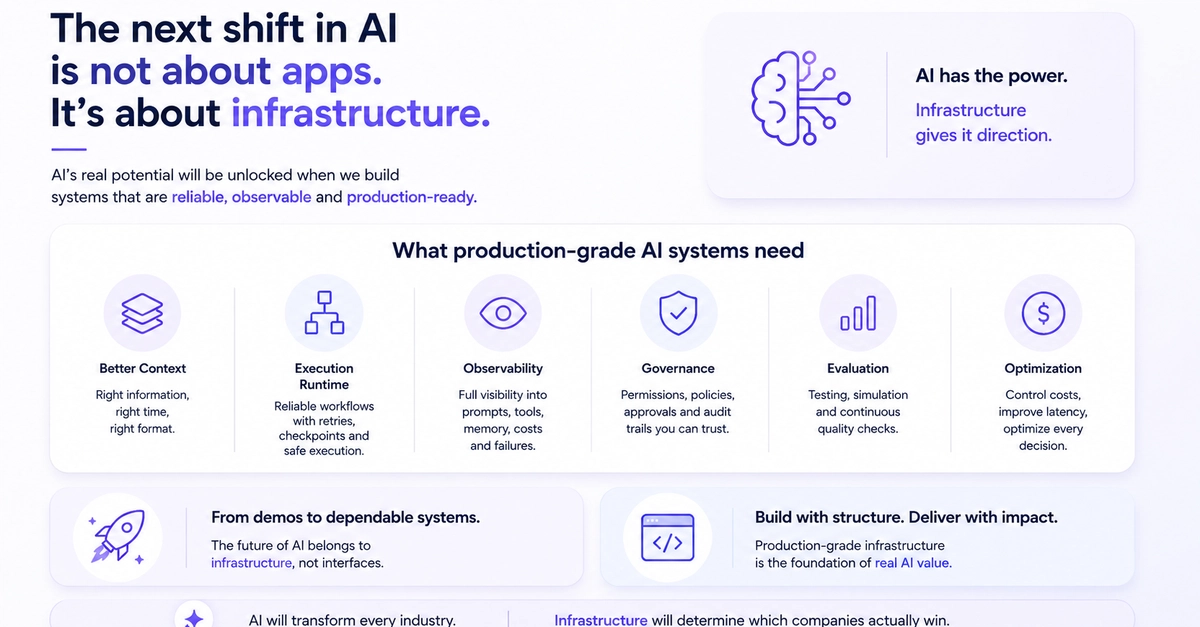
Introduction: The Day Your Demo Dies
Every LLM engineer has a moment like this.
Your demo works flawlessly. A clean API, a responsive model, maybe even a RAG pipeline that feels “intelligent.” You deploy it, share it, and everything looks promising.
Then real users arrive.
Requests start piling up. Latency becomes unpredictable. Some responses take seconds, others timeout. GPU memory spikes. One of your services crashes—and suddenly the entire pipeline stops responding.