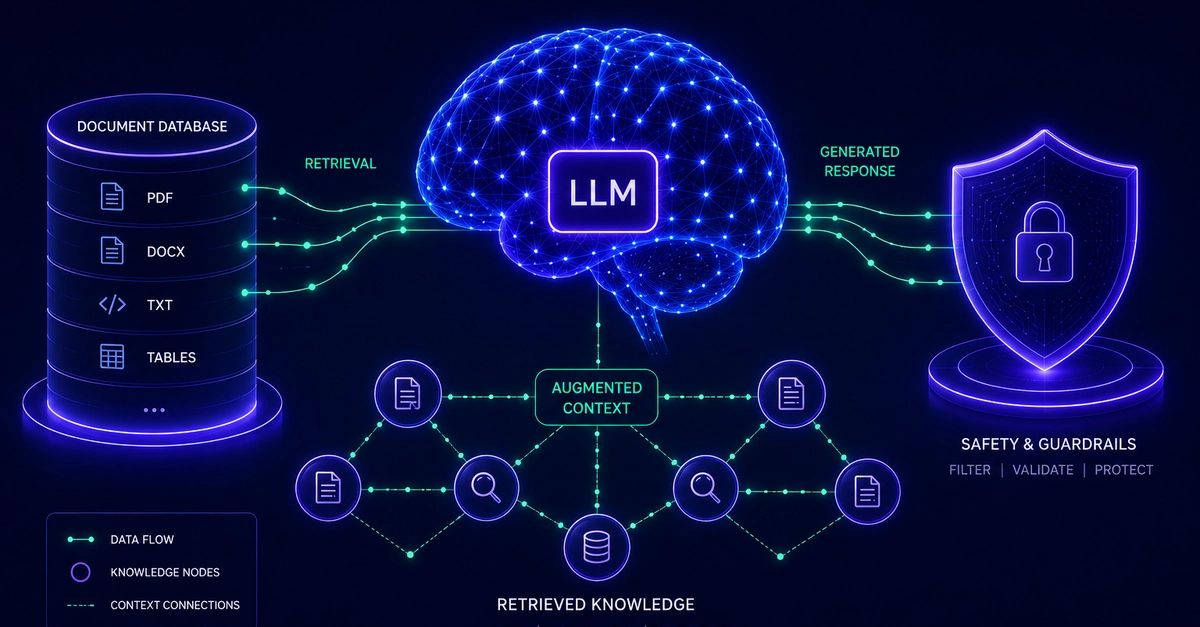
Most teams that try RAG (retrieval-augmented generation) get it working in a weekend. Getting it to stay working at scale is the harder problem. According to a 2024 report on enterprise AI adoption, over 60% of AI pilot projects stall before production because of infrastructure and data pipeline issues, not model quality. The stack matters. So does the architecture.
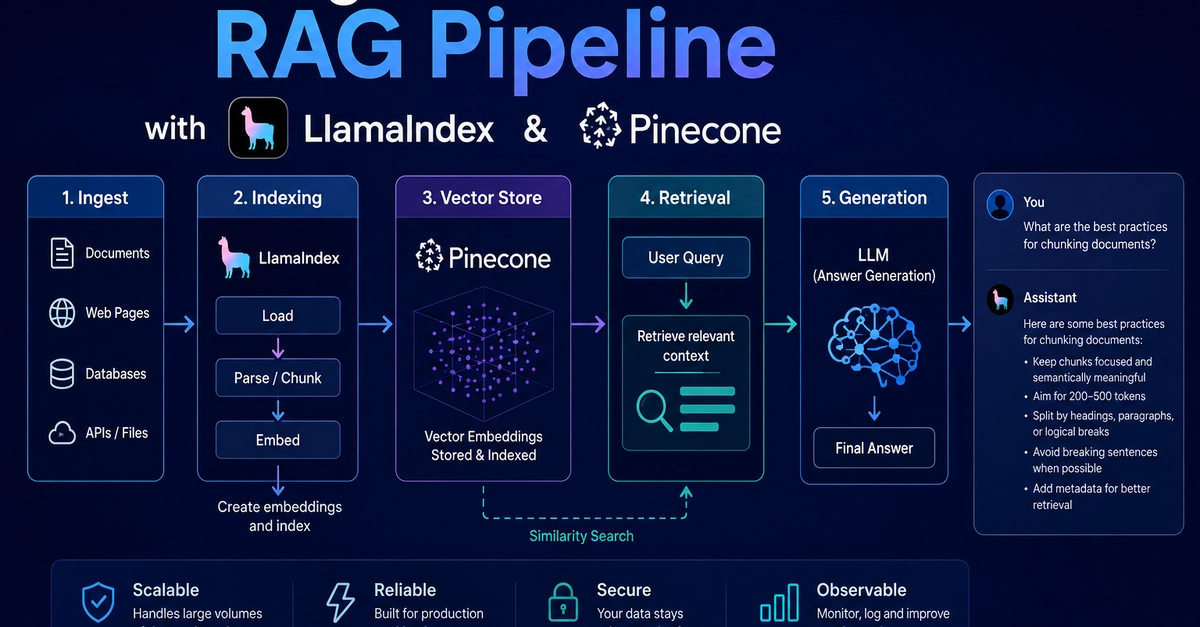
LlamaIndex and Pinecone have become a reliable combination for production RAG systems. LlamaIndex handles the orchestration layer, and Pinecone manages vector storage and retrieval at scale. This guide covers how to wire them together correctly, what breaks in production, and how to avoid the most common mistakes.
What a Production RAG Pipeline Actually Does
A demo RAG system answers questions. A production RAG system does that reliably, at volume, with fresh data, and for the right users.
The pipeline has six stages, and each one introduces failure points.