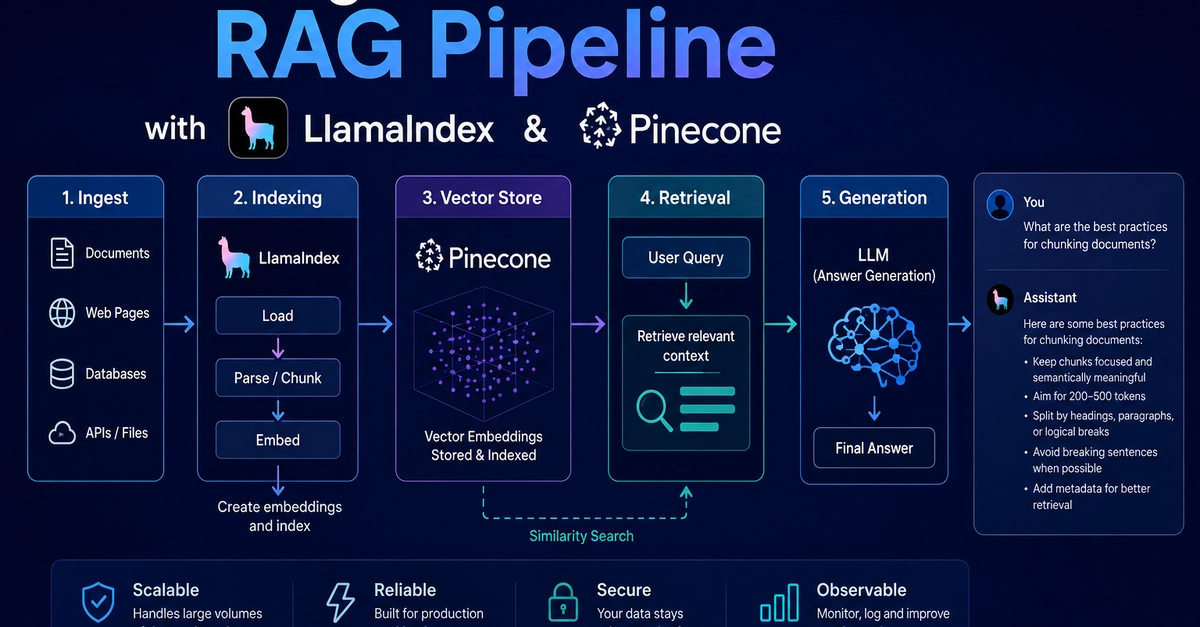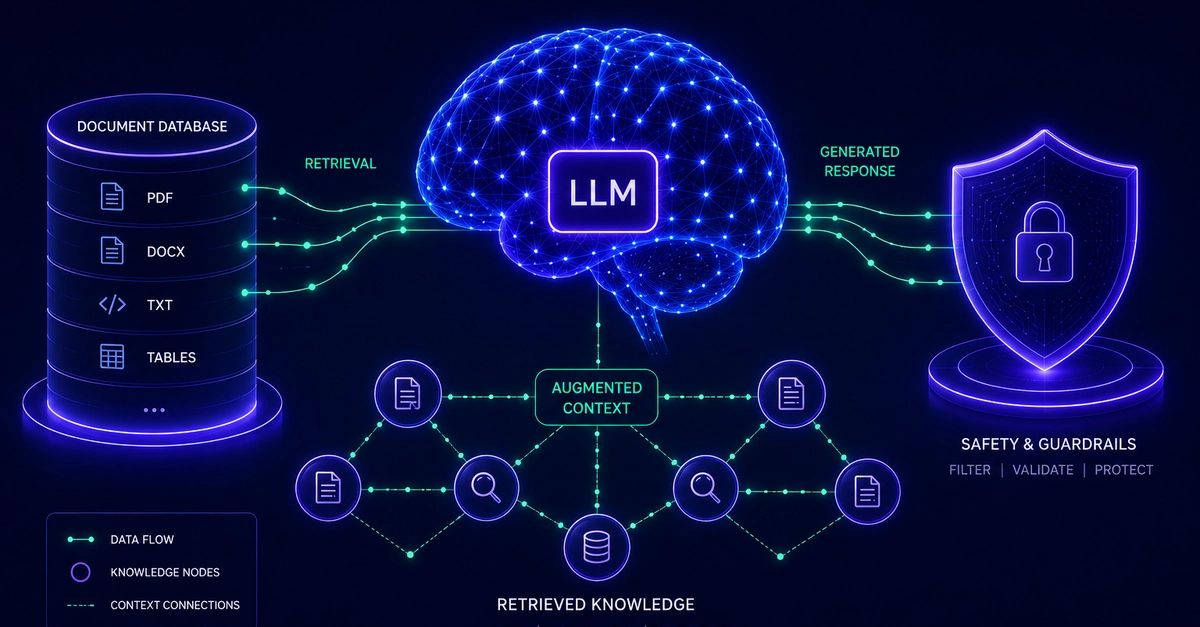
Building a basic Retrieval-Augmented Generation (RAG) prototype is a weekend project. You pip install an orchestration library, load a small text file, and throw raw strings at the OpenAI API.
But taking that prototype into production is an entirely different engineering challenge.
In a real-world enterprise environment, native LLM implementations quickly break down due to three severe operational bugs:
Unpredictable API token burn
High inference latency