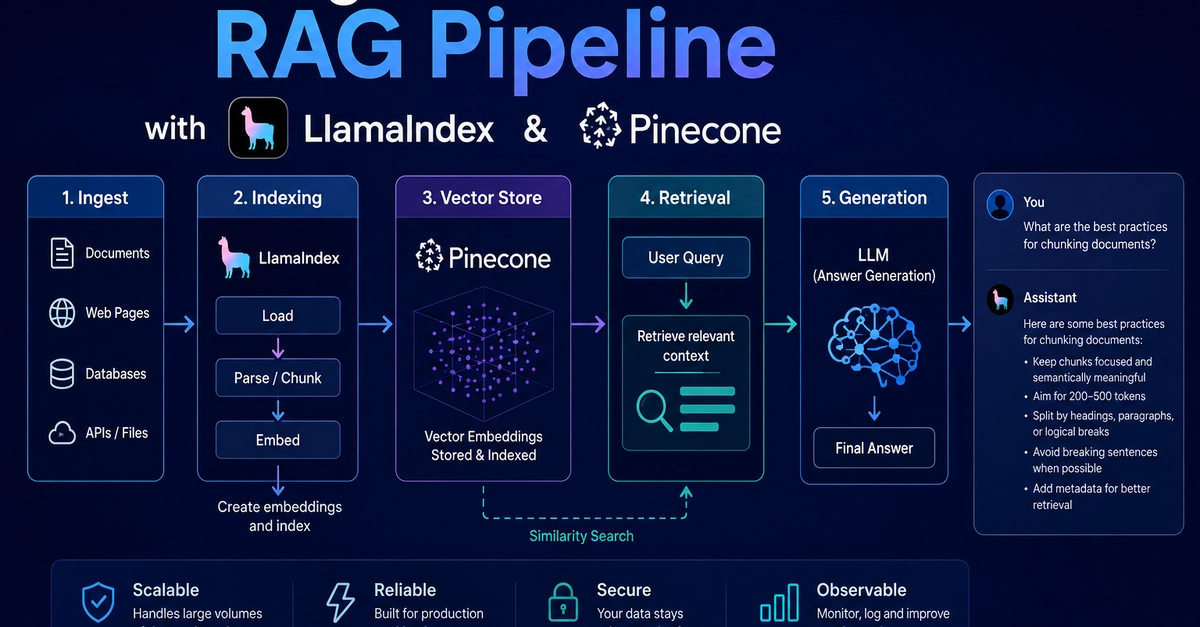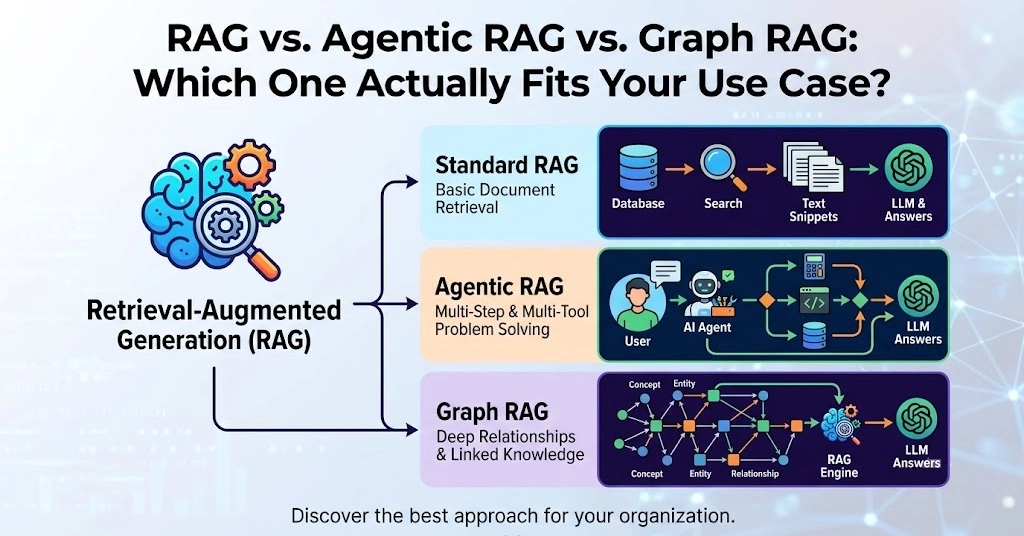
RAG has become the default answer for giving LLMs access to private knowledge. And for good reason — it works. But after running it in production we kept hitting the same wall. Not retrieval accuracy. The operational tax.
Re-embedding on data changes. Chunking drift. Retrieval misses on edge cases. Pipeline failures at 2am. The vector database that needs babysitting.
So we ran an experiment.
The Hypothesis
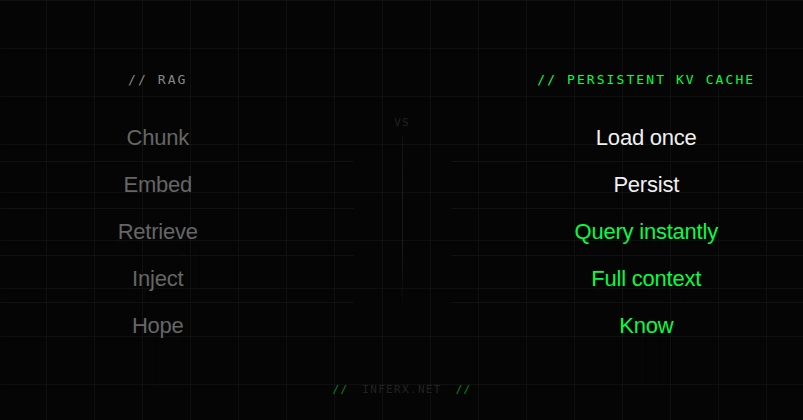
What if instead of chunking, embedding, and retrieving — we just loaded the full document into the LLM context, cached the KV state persistently, and reused it across every query?