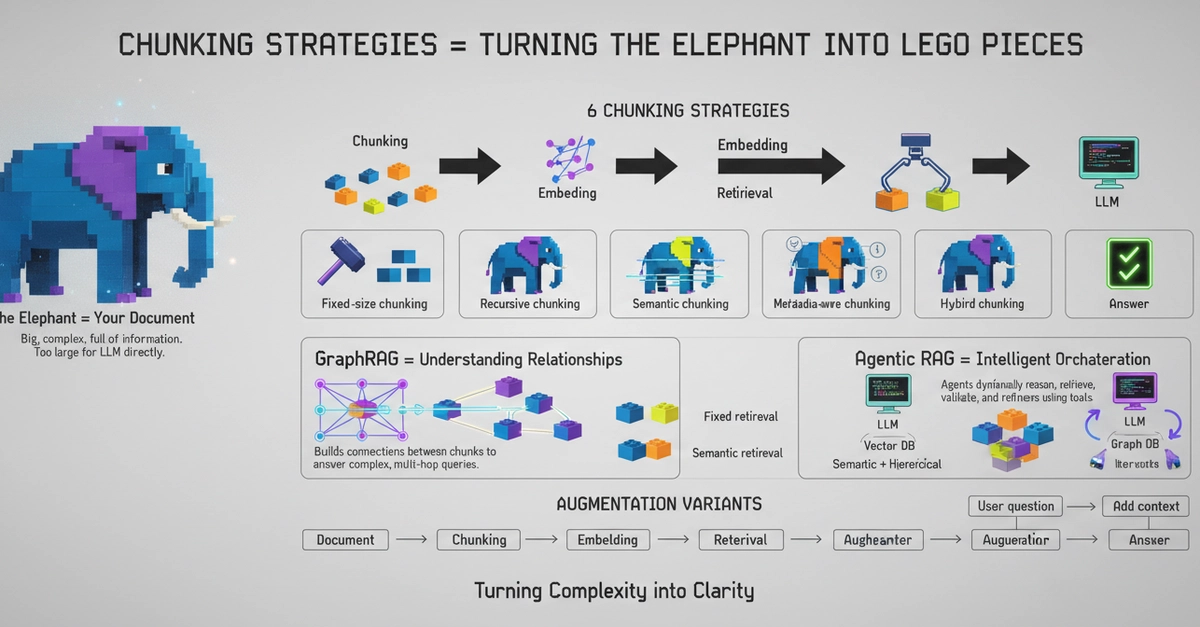
The Problem
You want to feed documentation into your RAG pipeline, but web scraping gives you a mess of navigation, sidebars, cookie banners, and broken formatting mixed with actual content. You spend hours cleaning up HTML before you can even start building your knowledge base.
The Solution
I built an automated extraction + chunking pipeline that converts any documentation site into clean, structured markdown ready for your vector store.
Step 1: Extract and Chunk the Docs