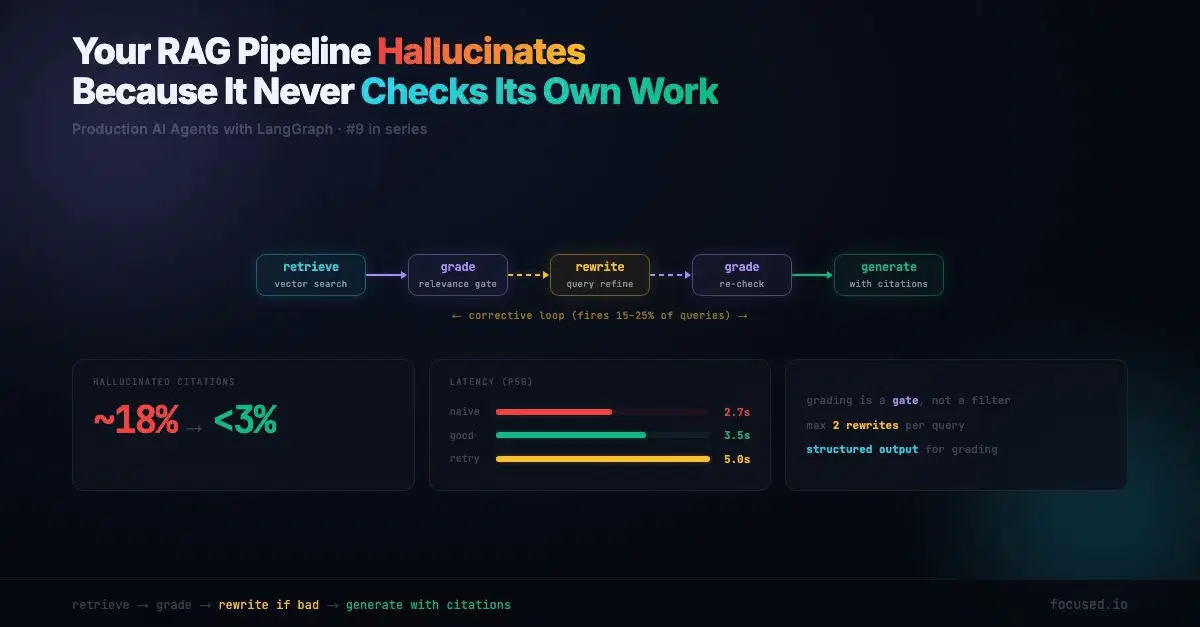
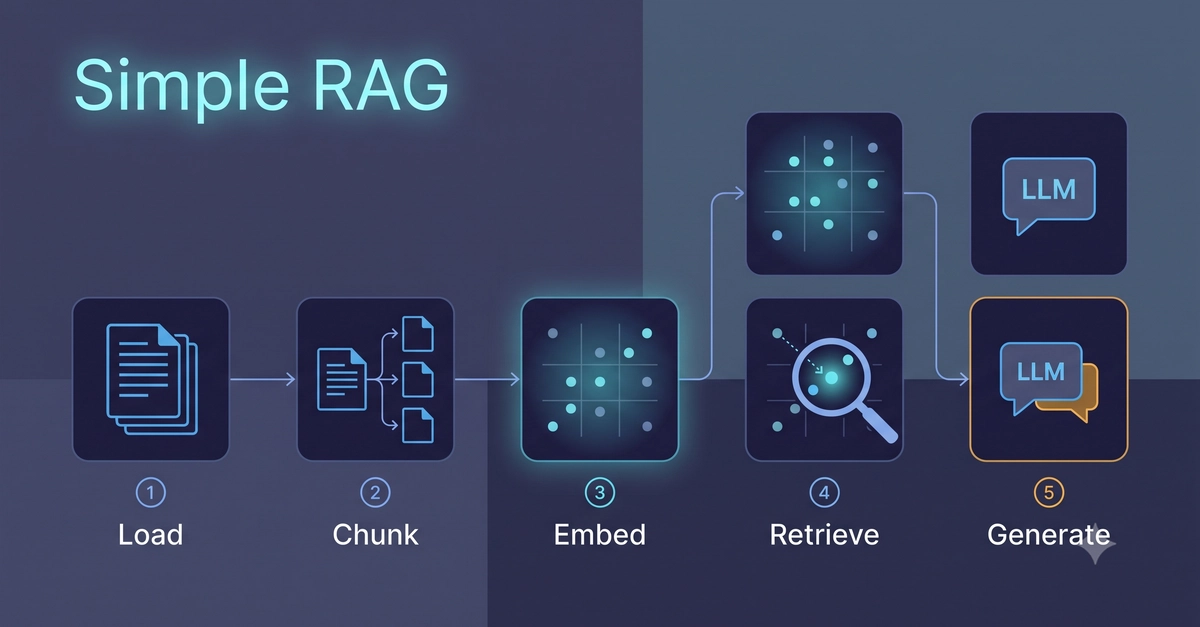
Three weeks ago I needed a way to query a large document corpus without sending everything to an LLM every time. The answer was a RAG (Retrieval-Augmented Generation) pipeline — but I wanted to build it inside n8n, not a Python script that I'd have to maintain separately.
Here's the architecture I landed on, and why each decision was made.
The Problem
I had 3,000+ pages of documentation spread across Google Drive. I needed Claude to answer questions about it accurately — not hallucinate, not miss context, not time out from context window limits.
Sending all 3,000 pages to Claude on every query wasn't viable. Cost, latency, and context limits made it impossible.