Your team ships a documentation chatbot. It retrieves chunks, stuffs them into a prompt, and generates an answer. Demo day goes great. Then a customer asks "what's the rate limit for the batch API?" and the bot confidently answers "10,000 requests per minute" — citing a doc about a completely different API. Nobody catches it because the answer sounds plausible.
This is the core failure mode of naive RAG: the retriever returns something, the generator uses it, and nobody checks whether the retrieved context actually answers the question. The fix isn't better embeddings or bigger context windows. The fix is a pipeline that grades its own retrieval, rewrites the query when results are poor, and refuses to generate when the context doesn't support an answer.
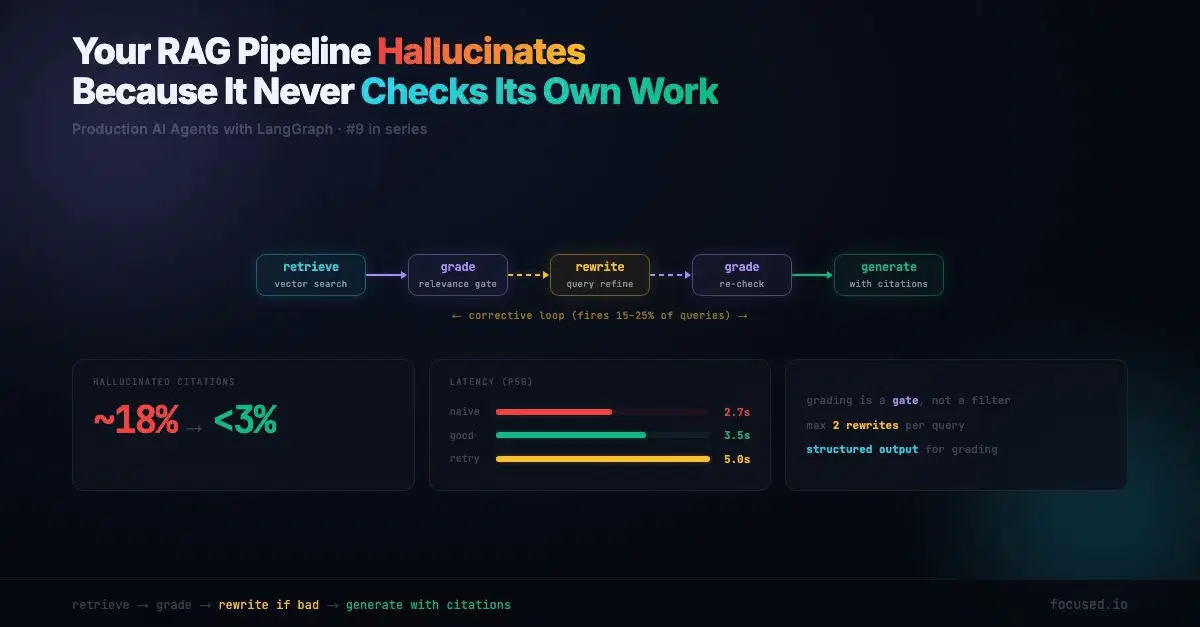
This post builds a corrective RAG pipeline using LangGraph. Retrieve, grade, rewrite if needed, generate with citations. The architecture adds ~1.5 seconds of latency on the retry path but drops hallucinated citations from ~18% to under 3% in our evals. That's not a prompt trick — it's structural.
The Latency Math
Naive RAG is fast because it skips the hard parts:





