You deployed a RAG chatbot. The answers are vague. You bump the LLM from GPT-3.5 to GPT-4. The answers are still vague. You double the chunk size. Still vague. You spend three hours tuning prompts. Still. Vague.
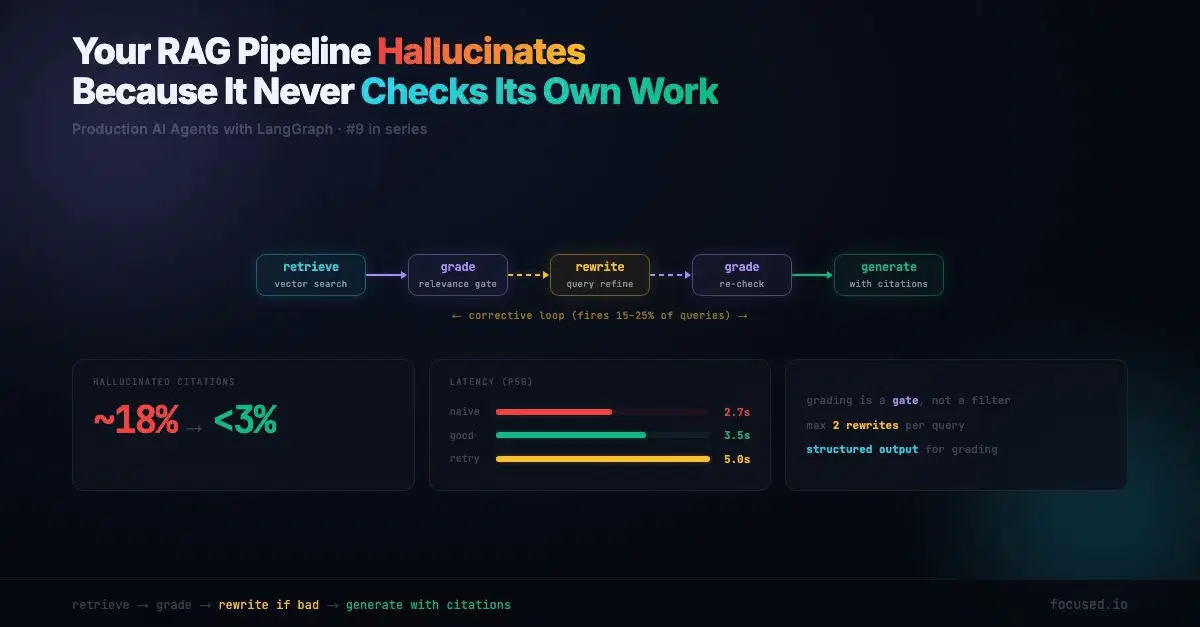
The real problem isn't the model. It's that your pipeline is retrieving 10 chunks and the LLM is only seeing 3 of them — and nothing in your logs tells you that.
What's Actually Breaking (and Why You Can't See It)
A RAG pipeline has at least two moving parts between a user query and an answer: a retrieval step that fetches relevant chunks from a vector store, and an LLM call that uses those chunks to generate a response.
The failure mode that kills most RAG quality work is invisible: chunks are retrieved, then silently discarded before they reach the LLM prompt.