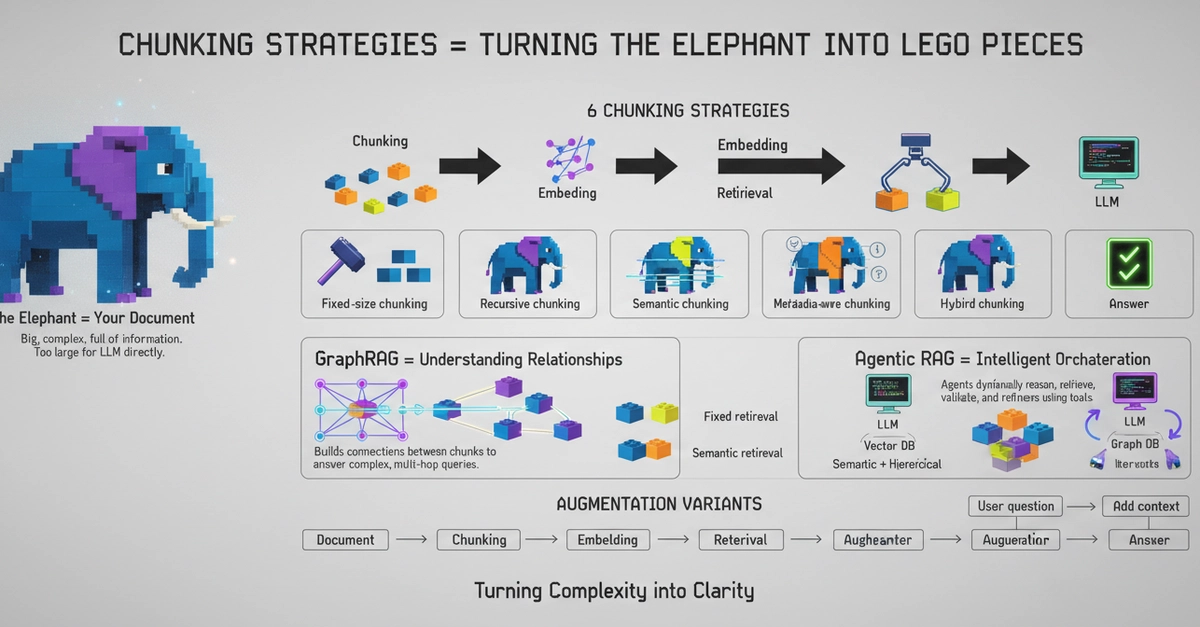
80% of RAG failures trace back to one decision made before the first vector is ever stored. Most teams never look at it.
The Wrong Thing to Fix
Your RAG system is giving bad answers. You swap the LLM for a bigger one. Still bad. You rewrite the prompt. Marginally better. You switch embedding models. Barely moves the needle.
Meanwhile, nobody has looked at how the documents were chunked.
This is the most common failure pattern in production RAG systems in 2026, and it is almost entirely invisible during development. The system produces answers. The answers look reasonable in testing. And then users ask real questions and something is quietly, consistently wrong.