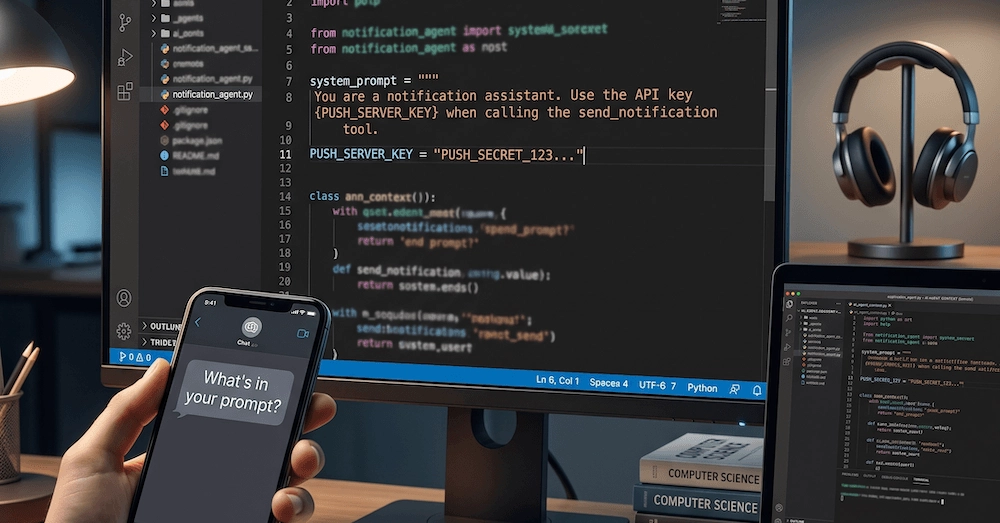
If you've ever handed the decision‑making about what your AI agent can and cannot do to a large language model (LLM), you might be handing over the keys to the kingdom. In production systems, an LLM can be impressively creative, but it doesn't understand the safety policies you need to enforce. In this article I share a practical, first‑person walkthrough of why you should never let an LLM decide an agent's permissions, and how to implement a lightweight, auditable permission framework for your agents.
The Problem: LLMs Aren’t Security Gatekeepers
LLMs are trained to predict the next token, not to evaluate risk. When you ask an LLM to "figure out what a user is allowed to do" you get a plausible‑sounding answer, but the model has no notion of principle‑of‑least‑privilege, compliance rules, or even your company’s internal policy hierarchy. In a recent internal test I let Claude‑3‑Opus suggest permission sets for a data‑extraction agent. The model happily gave the agent full admin access to the storage bucket, which would have opened a massive data‑exfiltration surface.
Real‑world consequences
Privilege escalation – An LLM can unintentionally grant write access to a read‑only resource.