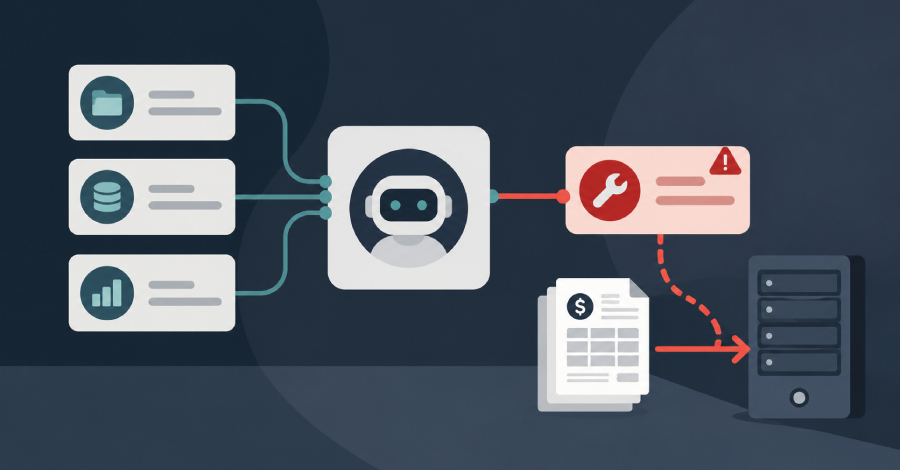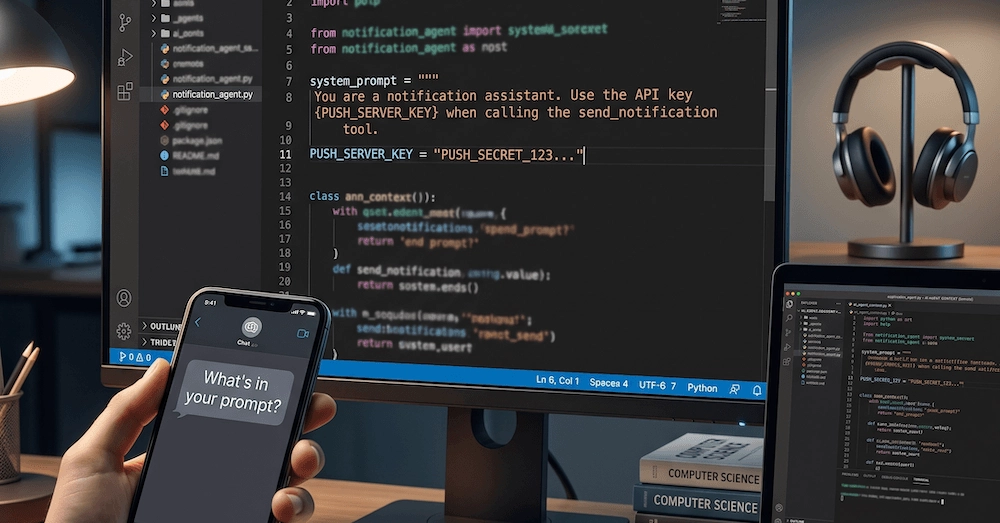
Some time ago, I reviewed an AI agent implementation and found an API key in the system prompt. The developer didn't realize it, but the LLM did.
LLMs cannot natively separate instructions from data. Whatever lands in the active context window is processed with equal access: system prompts, tool definitions, user messages, retrieved documents. The model sees all of it as tokens. It cannot tag some tokens as "sensitive" and others as "public". That's not how it works.
There's a direct consequence for secrets: if an API key, access token, or credential enters the context window, it's exposed. A curious user can ask for it. A malicious payload injected through a tool result can prompt the model to disclose it verbatim. The model might include it in a generated output you didn't anticipate.
The golden rule that follows is simple: if you don't want your AI agent to reveal a secret, don't give it access to that secret. The rest of this post shows where developers break this rule, why some of the mitigations they reach for don't actually help, and what the correct fix looks like.
Why AI Agents Are Prone to Leaking Sensitive Information