TODO: Remember to copy unique IDs whenever it needs used. i.e., URL: 304b2e42315e
Originally published on Towards AI.
When an LLM feature breaks in production, the first instinct in the room is to open the prompt and reword it. We had that instinct too. Then we built a production assistant for financial advisors and kept a record of every LLM-related failure the system hit, along with the fix that actually closed each one. Across the whole build, almost nothing that mattered was fixable by editing a prompt. The durable fixes were architectural. The single time we tried a prompt-only fix on the hardest problem, it made things measurably worse, and we reverted it.
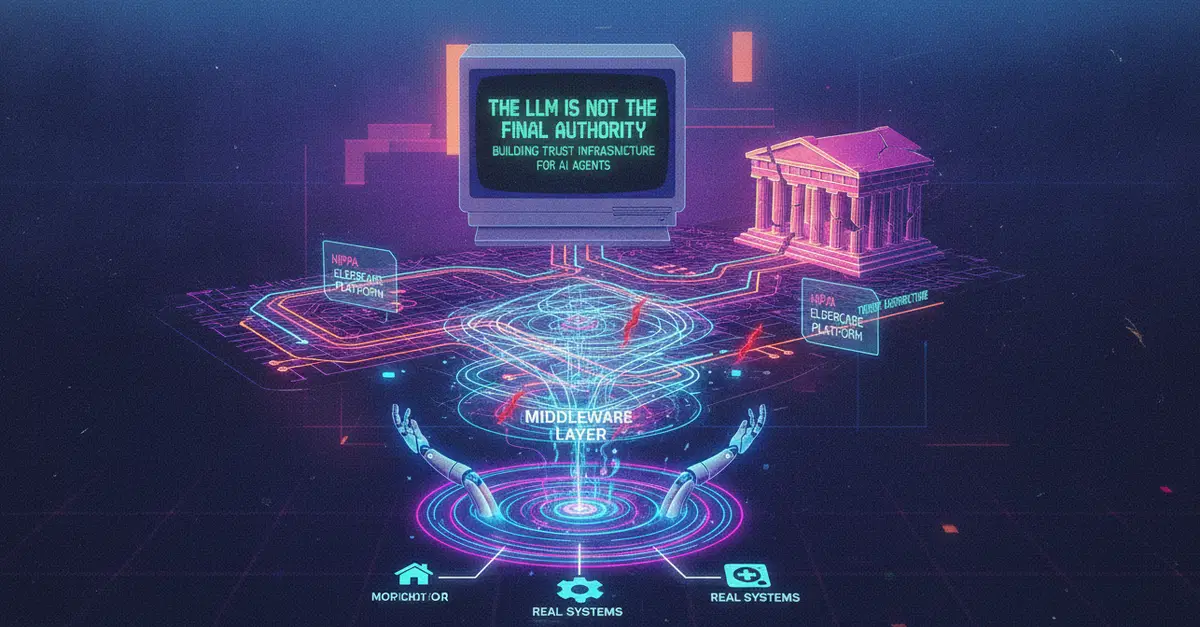
This is the case for treating the model as one untrusted component in a larger system, written from the failures that taught us to do it.
Routing was our most unstable surface, and it was unstable in a way that prompt editing could not reach. The same question routed one way on one run and a different way on the next, with no code change in between. On the ambiguous edges, routing accuracy sat around 56 to 64 percent and was non-deterministic from run to run. A question like “rank my households by AUM” came back as a clarification request on one run and a confident answer on the next.