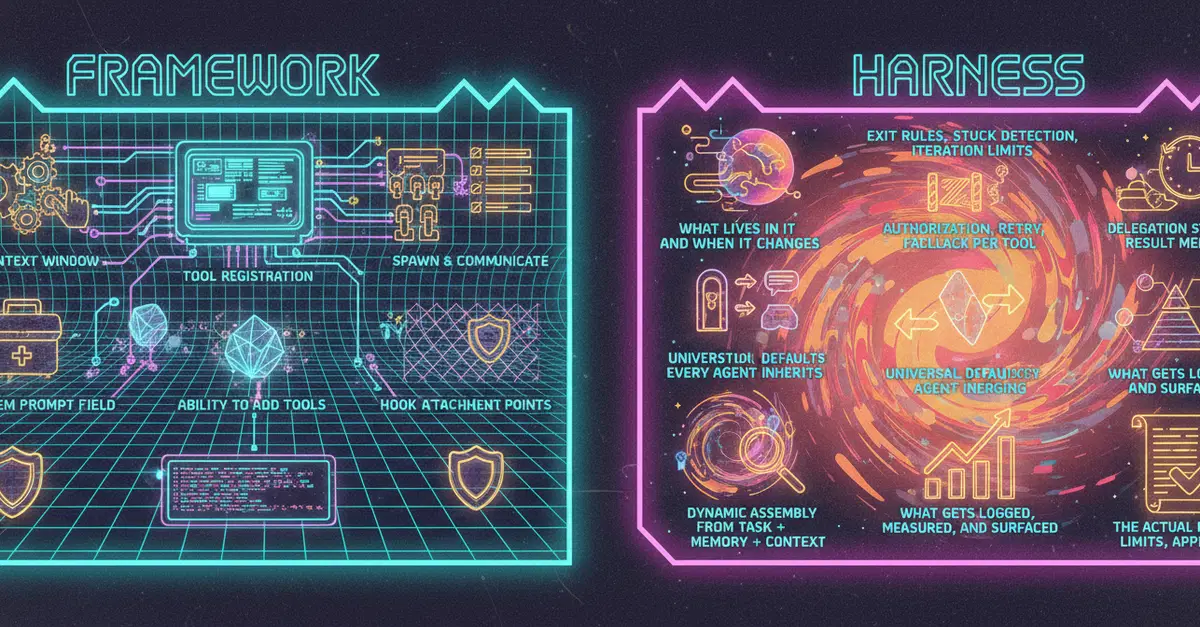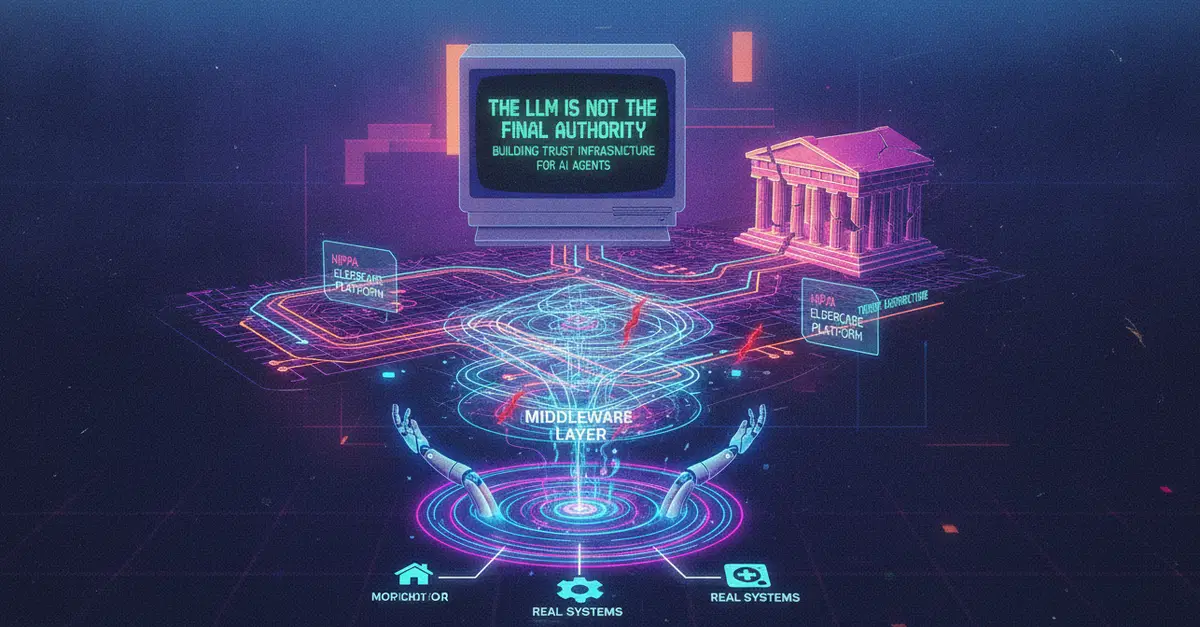
The Problem Nobody Wants to Say Out Loud
Most LLM agent deployments have a quiet assumption baked into their architecture: the model will behave.
Not because anyone decided this explicitly. It happened by default. You write a system prompt. You test it. The model behaves correctly in your test cases. You ship it. And then, in production, under real inputs from real users with real intent — some cooperative, some adversarial, some just unusual — the model does something unexpected.
And when that happens, you have three problems simultaneously.
You cannot prove what the model received as input. You cannot prove what it returned as output. You cannot prove whether any human was involved in the decision. You have logs, maybe. You have vibes about what probably happened. But you do not have evidence.