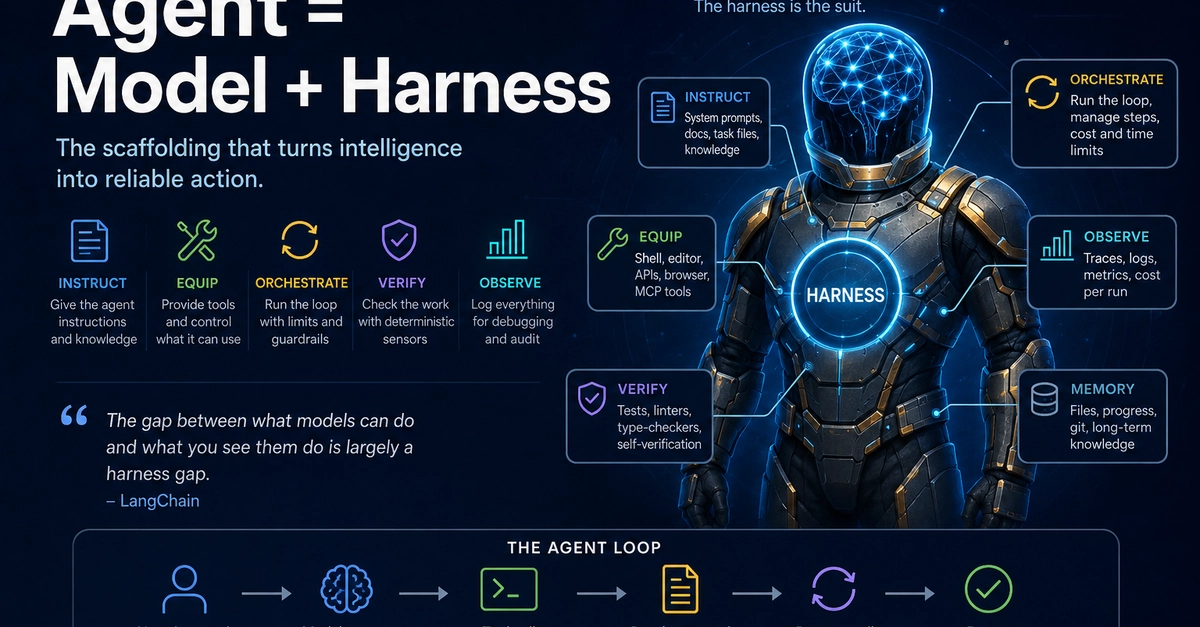
Agent harness design can deliver bigger gains on SWE‑Bench than upgrading the LLM. The Claw‑SWE‑Bench study shows that a well‑engineered adapter lifts Pass@1 by over 50 percentage points while keeping the same model [1].
Earlier evaluations of coding agents often treated the harness as a fixed plumbing layer and focused on model size or prompting tricks, without systematically studying the impact of patch‑extraction or workspace contracts.
With GLM 5.1, a minimal direct‑diff adapter scores 19.1 % Pass@1, but the full adapter reaches 73.4 %, a 54.3‑point improvement generated solely by harness tweaks [1].
When the model stays constant, changing the harness moves Pass@1 by roughly the same magnitude as swapping the model: model choice adds 29.4 pp whereas harness choice adds 27.4 pp [1].
The experiment evaluates 350 issues across eight languages using two backbone models (e.g., GLM 5.1 and Qwen 3.6‑flash) and also includes a sweep over nine different models, leaving open questions about scalability to larger code‑bases, domain‑specific tools, or alternative evaluation pipelines [1].