Everyone benchmarks the model. Almost nobody benchmarks the harness — the loop, the tool dispatch, the context manager, the retry logic that wraps a raw inference call and turns it into something that can run unattended against production. In my experience building agentic platforms, swapping the model is a config change you ship in an afternoon. The harness is where the months go, and it's where reliability is actually won or lost.
This is the part that doesn't show up in demos. A demo agent calls a tool, gets a clean result, and prints a tidy answer. A production agent calls a tool that times out, gets a 200 with a malformed body, hits a rate limit on retry, and now has to decide whether to keep going or give up — all while staying inside a token budget and not corrupting anything downstream. The model doesn't solve that. The harness does.
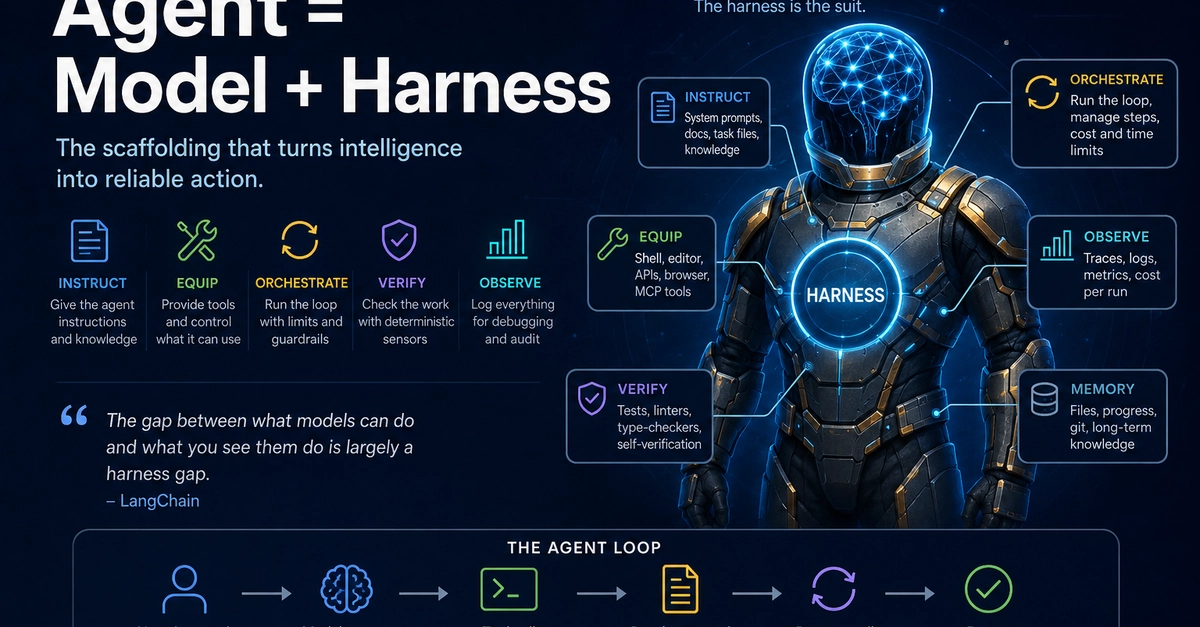
The harness is the product
When people say "we built an agent," they usually mean they wrote a prompt and a tool schema. That's the easy 20%. The other 80% is the scaffolding that decides when to call the model, what to put in front of it, whether to trust what comes back, and what to do when something fails. That scaffolding is the harness, and it's where your engineering judgment lives.