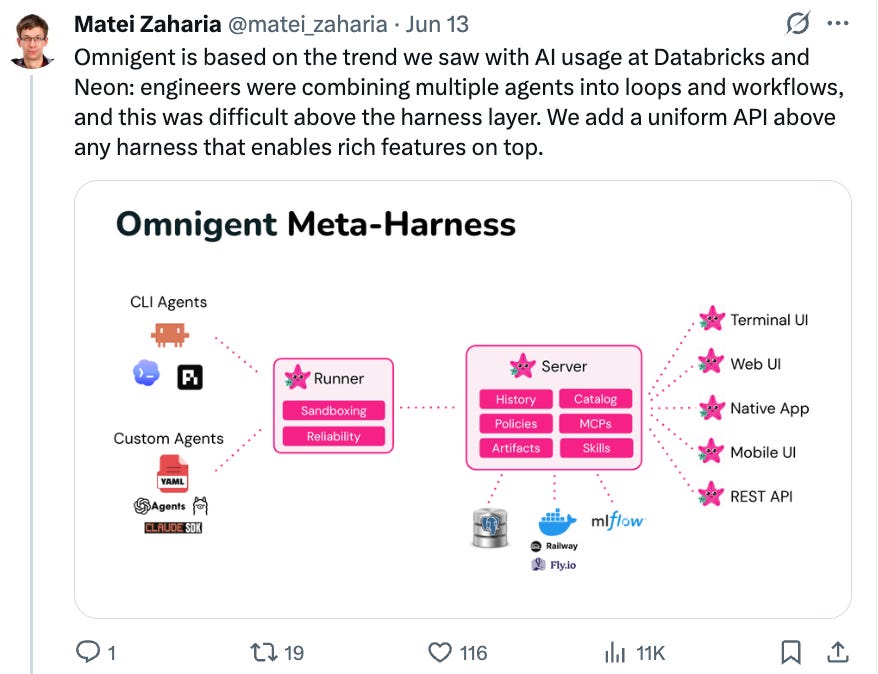
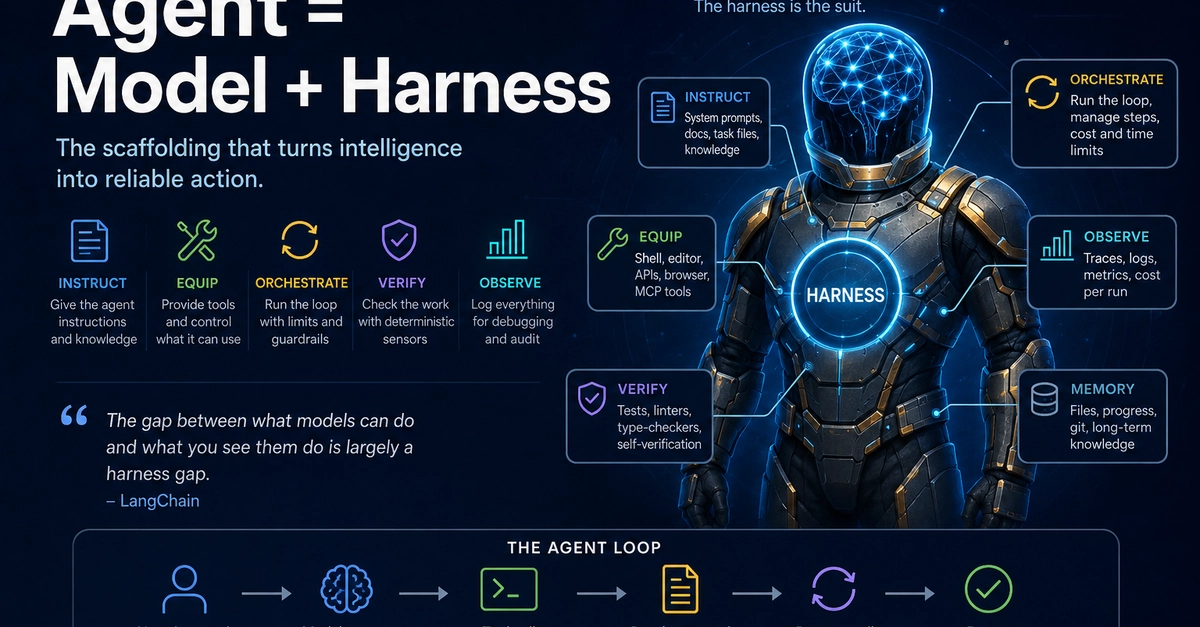
TL;DR — Harness engineering is one thing: getting reliable judgment out of a reasoner you didn't train — given an instruction, bounded by a spec that can override that instruction, and verified before the result ships. It is not "the wrapper around the model." It's a property of code, not a place in your stack, and it lives on both sides of every tool call. The generic scaffolding — loops, dispatch, memory — melts into the model a little more every quarter. What survives is the part that stays external to the model: the specification of what the agent may do, and the verification that it did. That's the discipline. The rest is plumbing.
I've written before that Agent = Model × Harness, and that the harness is the half you actually engineer. I still believe the formula. But stop there and it oversells two things — so this is me correcting my own framing, precisely, with code.
The two things the formula gets wrong
The × oversells separability. Multiplication implies the factors are independent. They aren't. A better model doesn't leave your harness untouched — it dissolves parts of it. Chain-of-thought prompting became reasoning models. ReAct-style tool loops became native tool use. Half your RAG plumbing is being quietly absorbed by longer context and better-trained retrieval. Every model generation collapses a layer of harness the previous one needed.