There's a formula I keep coming back to when people ask why their slick demo agent falls apart in production:
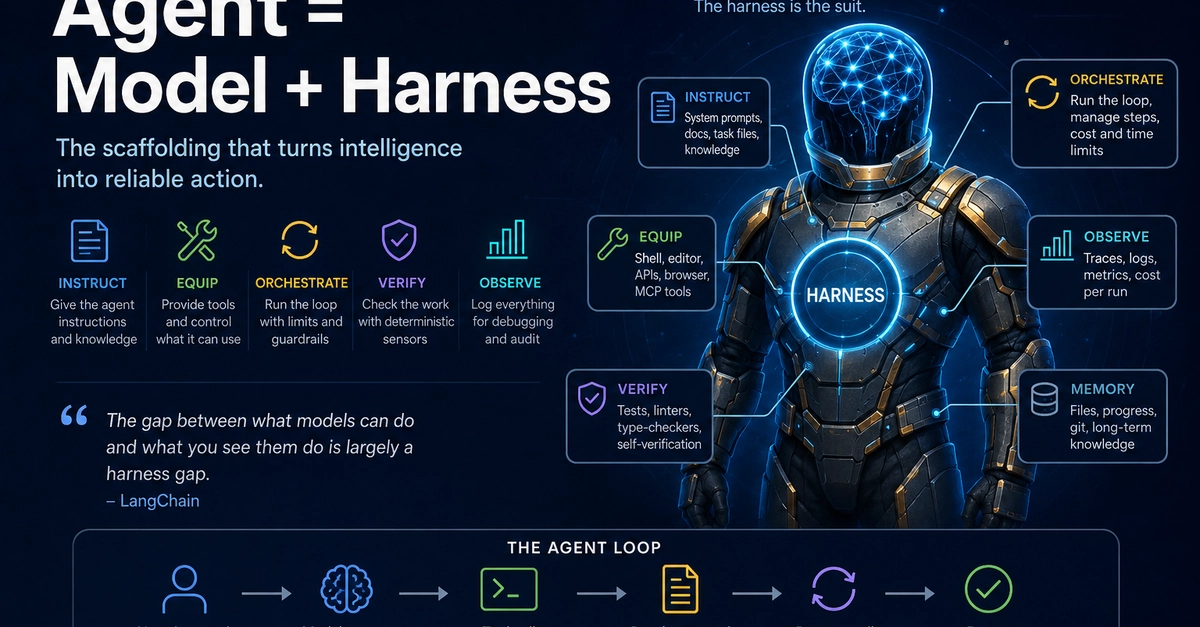
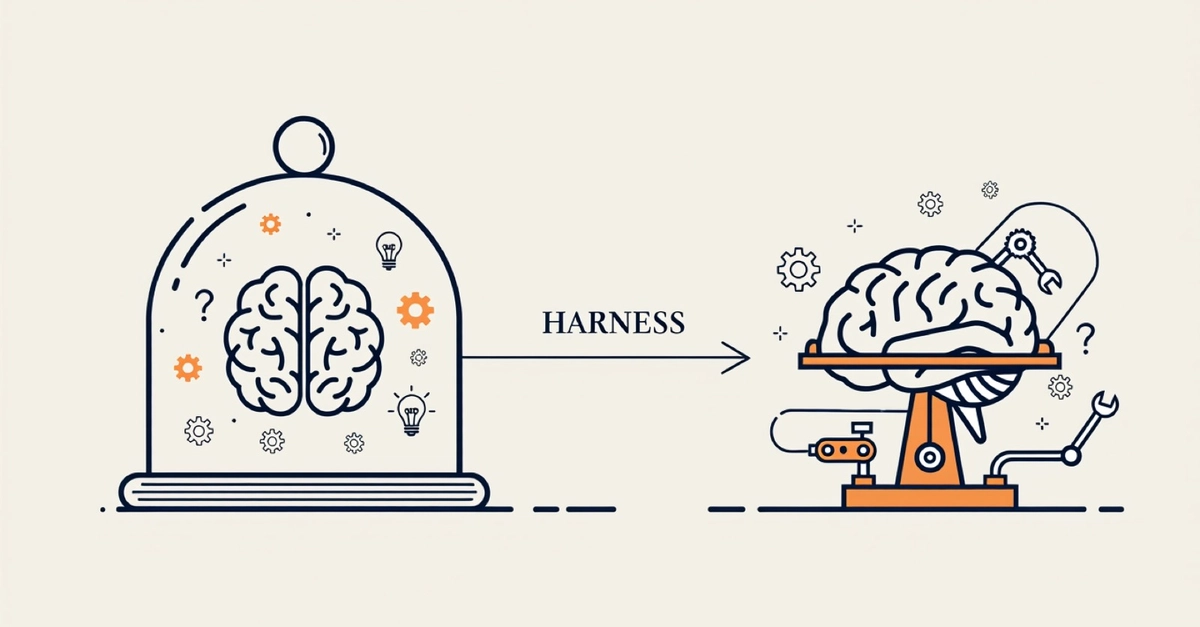
Agent = Model × Harness
The model is the raw reasoning — Claude, GPT, whatever. It's swappable, and it's getting better on a curve you don't control. The harness is everything else: the goals, the loops, the tools, the scheduler, the retry logic. Most of the engineering that matters lives in the harness, not the model.
But here's the part most teams get wrong. They define the harness as the plumbing to run the model — goals + loops + tools — and then bolt evals and observability on the side as external QA. Things you point at the agent, after the fact, from outside.
That's the mistake. Your eval layer and your trace layer are inside the harness. They're not tools beside the agent; they're the half of the agent that makes it a closed loop instead of an open one.