Tracing the LLM call is the easy 20 percent. For a voice agent, the failures live in the audio layer your tracer never sees.
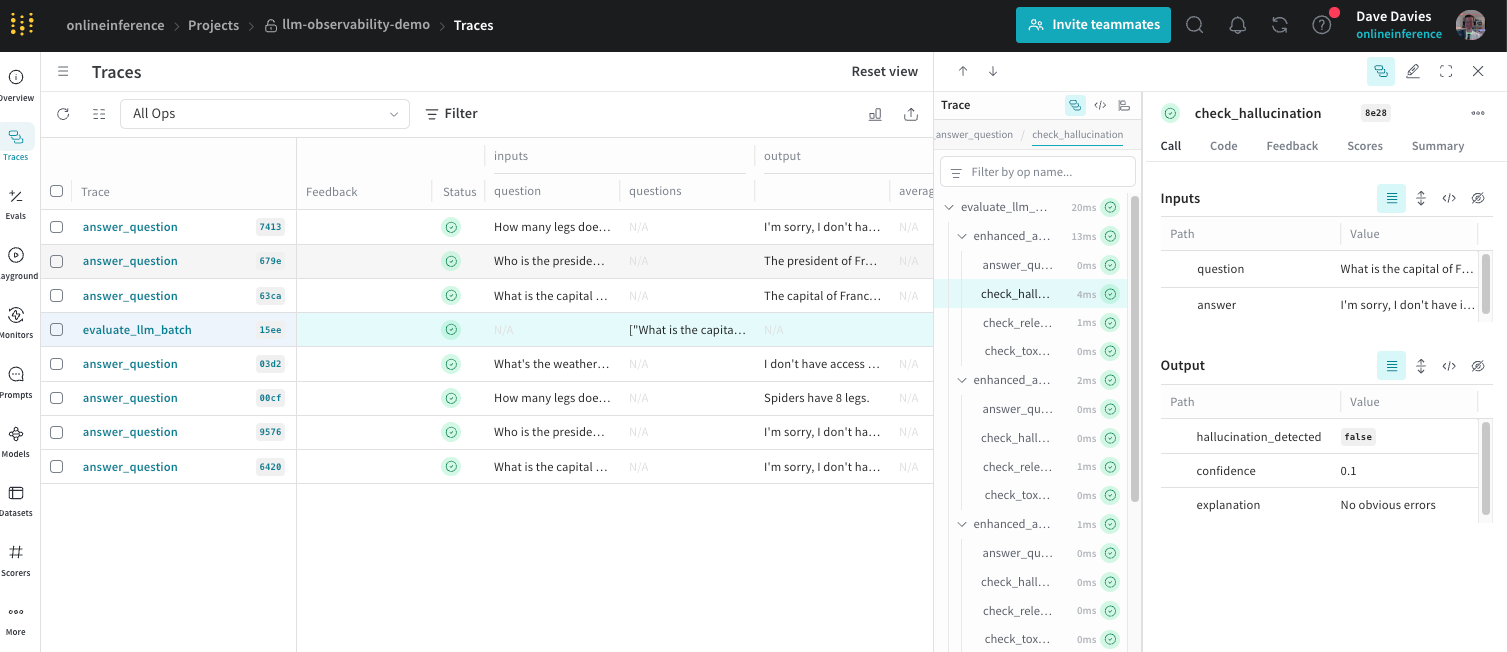
Most LLM observability tools trace the same thing: the prompt, the completion, the tokens, the latency of the model call. For a text agent that is most of the story. For a voice agent it is maybe a fifth of it, because the failures that actually make a voice agent feel broken happen in the audio layer, and a tracer pointed at the LLM call cannot see them. I went through six observability tools (Langfuse, Helicone, Arize Phoenix, LangSmith, Braintrust, and Laminar) asking one question each: can it show me the audio layer, or only the LLM call?
The audio layer is where the real spans are. End-of-turn detection: how long did the agent wait before deciding the caller was done? ASR latency and confidence: how long did transcription take, and how sure was it? Barge-in: did the caller interrupt, and did the agent yield? Time-to-first-audio: how long from the caller finishing to the agent making a sound? None of these are LLM-call metrics, and a green LLM-latency dashboard tells you nothing about any of them. I have watched a voice agent with a perfectly healthy model-call trace feel sluggish and rude to every caller, because the lag and the interruptions lived in spans the tracer was not capturing.