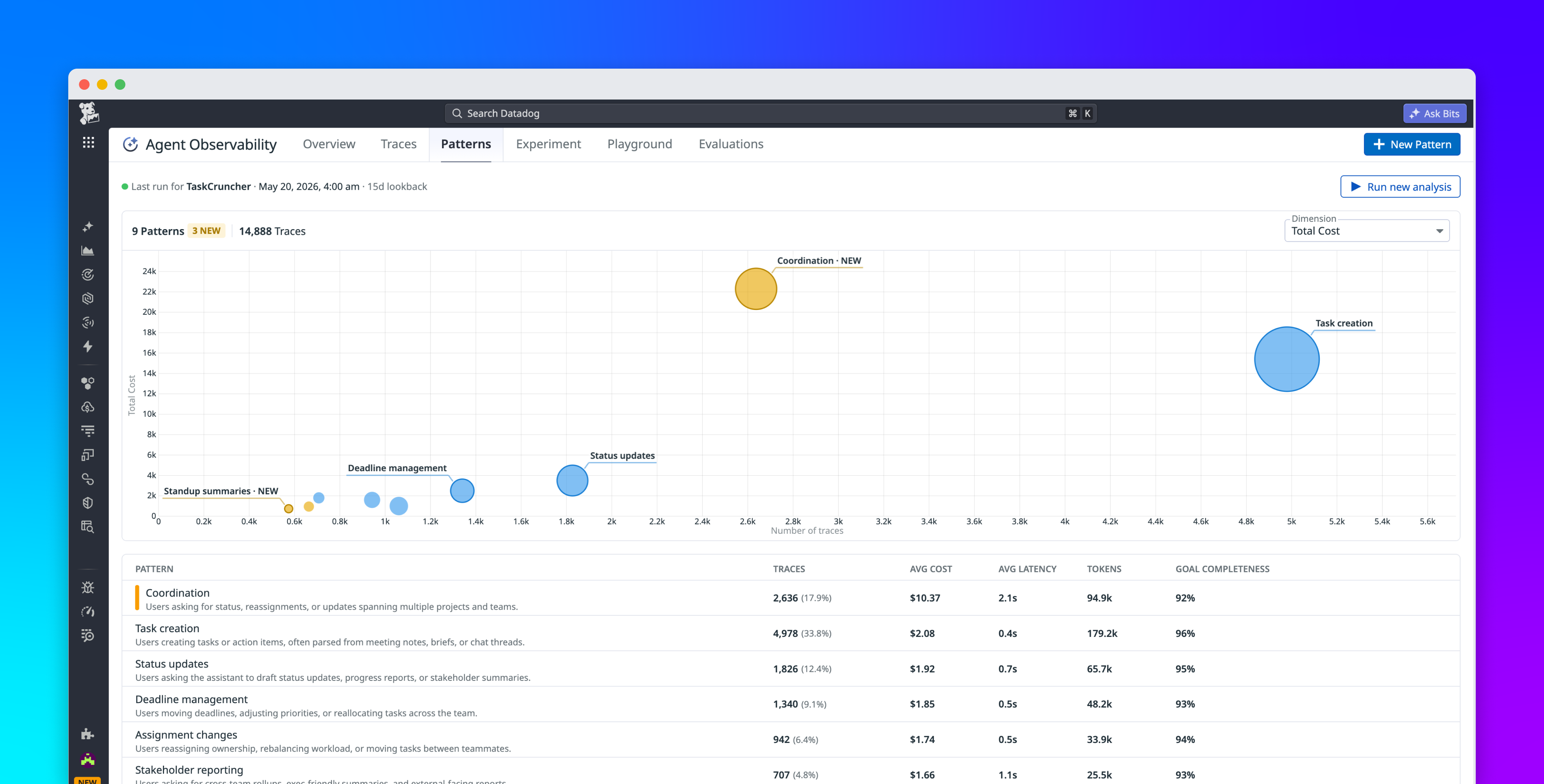
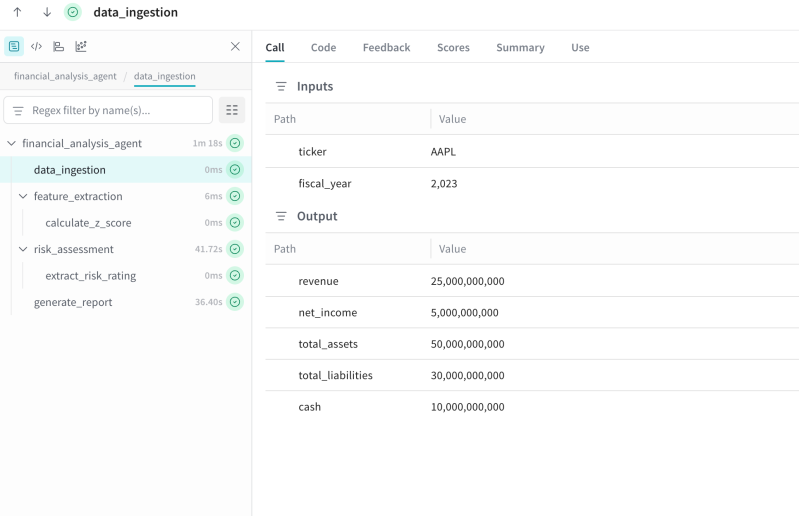
How application observability extends to stochastic agent loops — and why the tool boundary matters.
Production failures in LLM systems are often misattributed to the model. In practice, many incidents live in the action layer: a downstream API that time out, a tool that returns a business error inside a successful RPC, a subprocess the host spawned but never joined to the same trace. Standard logs capture completions; they rarely preserve the causal chain decision → tool invocation → observation → next decision.
This article is about that gap. It compares classic APM to agent telemetry, explains how the Model Context Protocol (MCP) gives observability a stable integration point, and points to a minimal reference stack (OpenTelemetry, optional Logfire, Jaeger) where host and tool server share one trace_id.
Reference implementation: github.com/ekb-dev-ai/mcp-trace-demo
LLM telemetry vs classic APM — and what MCP transfers