**
How I instrument ASR, LLM, TTS, and the client with OpenTelemetry, and which number in each layer I actually look at
**
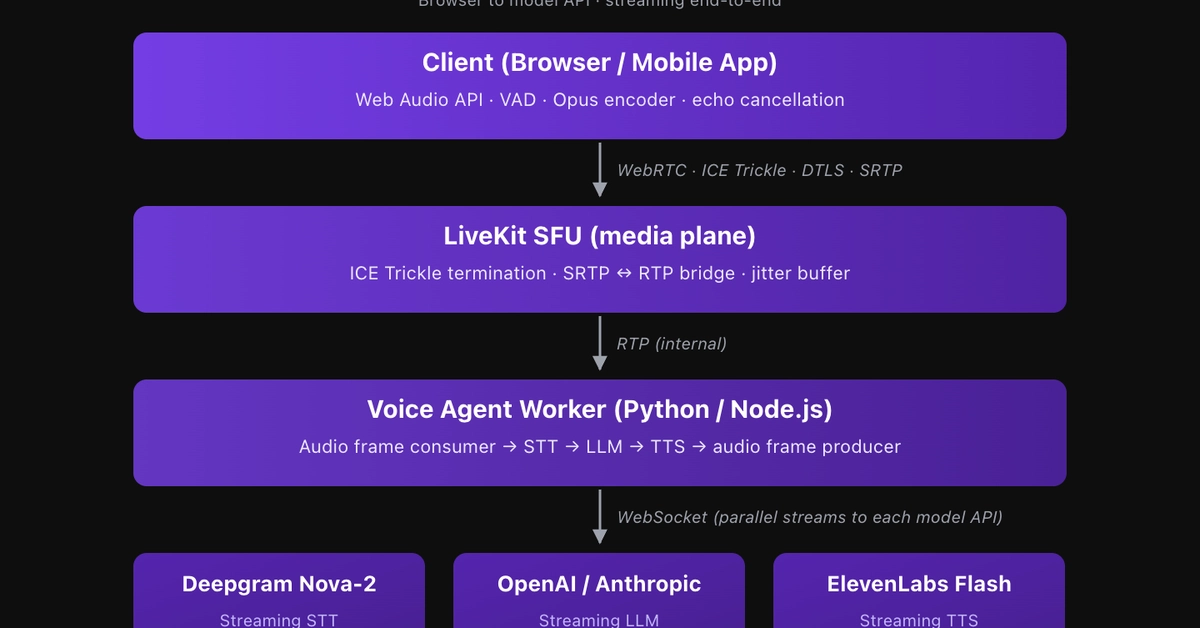
TL;DR. A voice agent is four moving parts stuck together: speech to text, the model that writes the reply, text to speech, and the client that plays the audio back. End to end latency hides which of those four is slow on any given turn, so I stopped tracking it as one number and started tracing each stage as its own OTel span with a shared session id. The number I watch hardest is barge-in: when the user starts talking over the agent, how many milliseconds until the agent actually stops sending audio. In our setup we want that under 200ms, and when p95 barge-in creeps past that, the agent feels like it is talking at you instead of with you. Everything below is how I wire the spans, what attributes go on each one, and the p95 I page on per layer.
The thing I keep saying, and the thing that keeps being true: voice agents fail in production not because of raw latency but because nobody simulated the audio and LLM pipeline together. You can have a fast ASR, a fast model, a fast TTS, and a voice agent that still feels broken, because the failure lives in the seams between them and in the parts (barge-in, jitter) that no single-stage benchmark touches. Tracing is how I get the seams to show up.