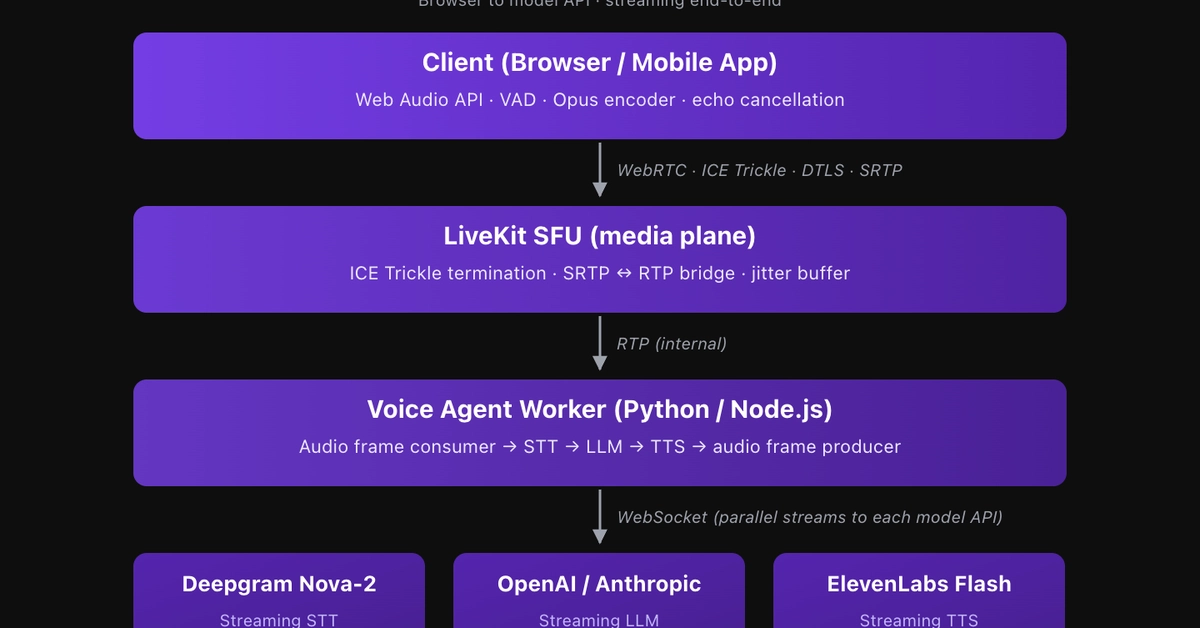
I kept reading that voice AI agents respond in under 300ms. AssemblyAI says it, Vapi says it, every Realtime API launch post says it. So I built five stacks, dropped a stopwatch into each pipeline, and ran the same one-minute conversation through all of them.
Three of the five never came close.
The other two were the ones I had quietly assumed were "marketing numbers." Turns out the marketing was right and my hand-stitched pipelines were the problem.
The three cliffs nobody puts on the slide
Before the numbers, the perception model. Voice latency does not degrade smoothly. It falls off cliffs. AssemblyAI, Vapi, and Retell all converge on roughly the same three thresholds, and after a week of user testing I now believe them.