Atindra Jha, Naomi Sagan, Keisuke Kamahori, Xikai(Noah) Meng, Luke Zettlemoyer, Olivia Hsu, Jure Leskovec, Baris Kasikci, Stephanie Wang
June 15, 2026
Stanford University · University of Washington · Correspondence: atindra@cs.stanford.edu
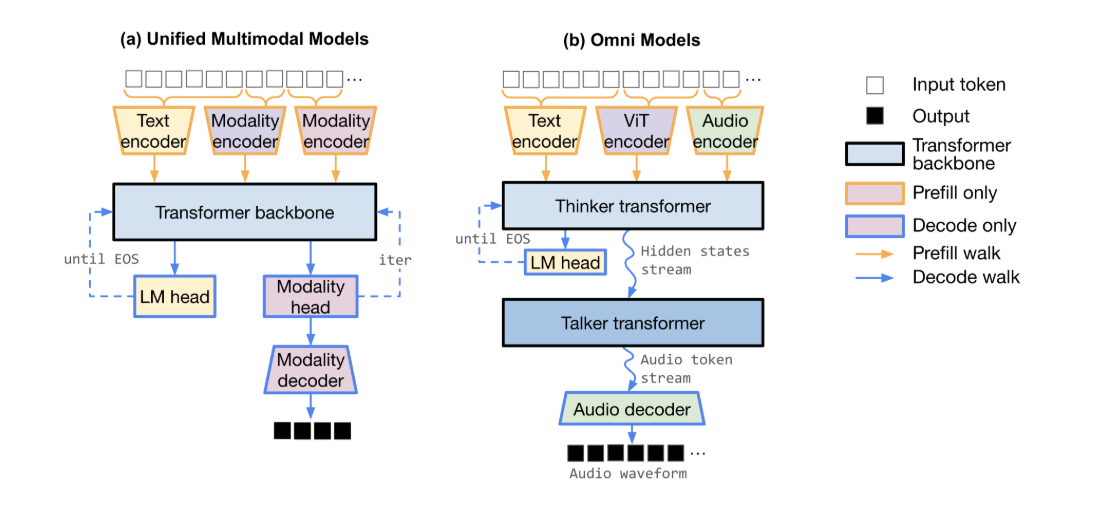
Today's models no longer fit the mold of autoregressive token generation, but the systems supporting LLM inference have not kept up. These models have composite architectures best captured by dataflow graphs. Requests are just walks on these graphs. M* is designed to fit this paradigm and maximize flexibility and performance for current and future composite models. In our tests, M* achieves nearly 2.7x higher throughput vs. vLLM-Omni and 4x higher throughput vs. SGLang-Omni while maintaining a lower RTF than both on Qwen3-Omni TTS workload.
Inference is no longer a single loop