Multimodal understanding has moved from research curiosity to production requirement. Systems that can jointly reason over text and visual inputs now power applications ranging from document extraction to autonomous agents. For developers building these pipelines, the infrastructure challenge is not only model selection but also managing context windows that swell when high-resolution images are encoded as tokens. Oxlo.ai addresses this through request-based pricing and a fully OpenAI-compatible vision stack, making it a practical backbone for multimodal workloads.
Architecture Patterns for Vision-Language Integration
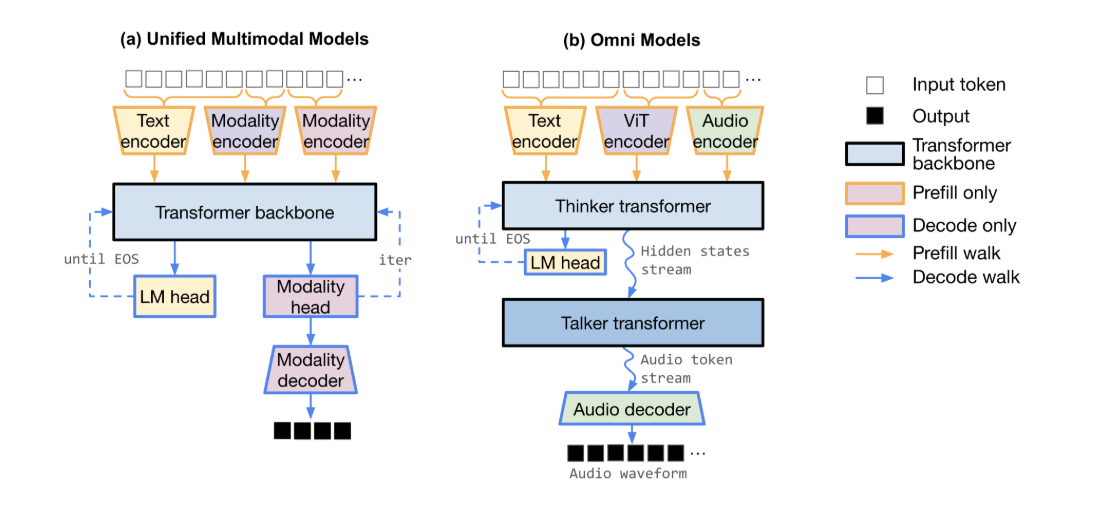
Most production multimodal systems follow one of two patterns. The first is the monolithic vision-language model, where image tokens are fed directly into a transformer alongside text. The second is a compositional pipeline, in which dedicated computer vision models handle detection or segmentation, and a separate large language model reasons over the structured results.
Oxlo.ai supports both approaches. Its catalog includes vision-native chat models such as Gemma 3 27B and Kimi VL A3B, as well as general-purpose reasoning models like Qwen 3 32B and DeepSeek R1 671B MoE that can consume structured visual data. For detection tasks, Oxlo.ai offers YOLOv9 and YOLOv11, while image generation is handled by Flux.1, Stable Diffusion 3.5, and Oxlo.ai Image Pro. This lets you keep a single API key and base URL for an entire multimodal stack.