Home
Storia in 1 fonti
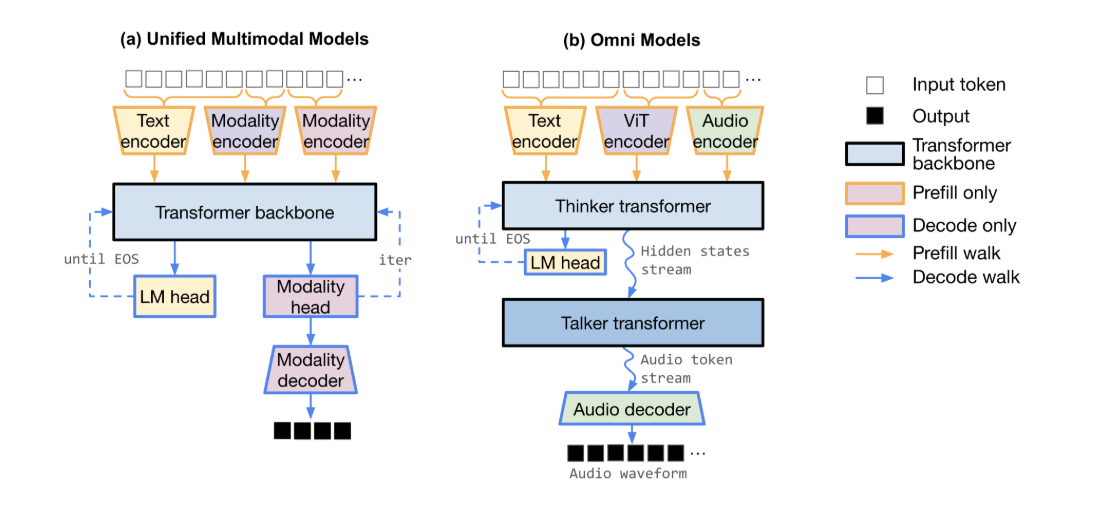
M*: A Modular, Extensible, Serving System for Multimodal Models
M* is a modular serving system for multimodal models that achieves up to 2.7x higher throughput vs. vLLM-Omni and 4x vs. SGLang-Omni on composite model workloads.
Raccontata da ai.stanford.edu
ai.stanford.edu