
Fonte
ai.stanford.edu
21articoli totali nell'archivio





Fantastic Bugs and Where to Find Them in AI Benchmarks
TL;DR - It is not unusual that AI benchmarks contain flawed questions and are improperly graded, which undermines evaluation…
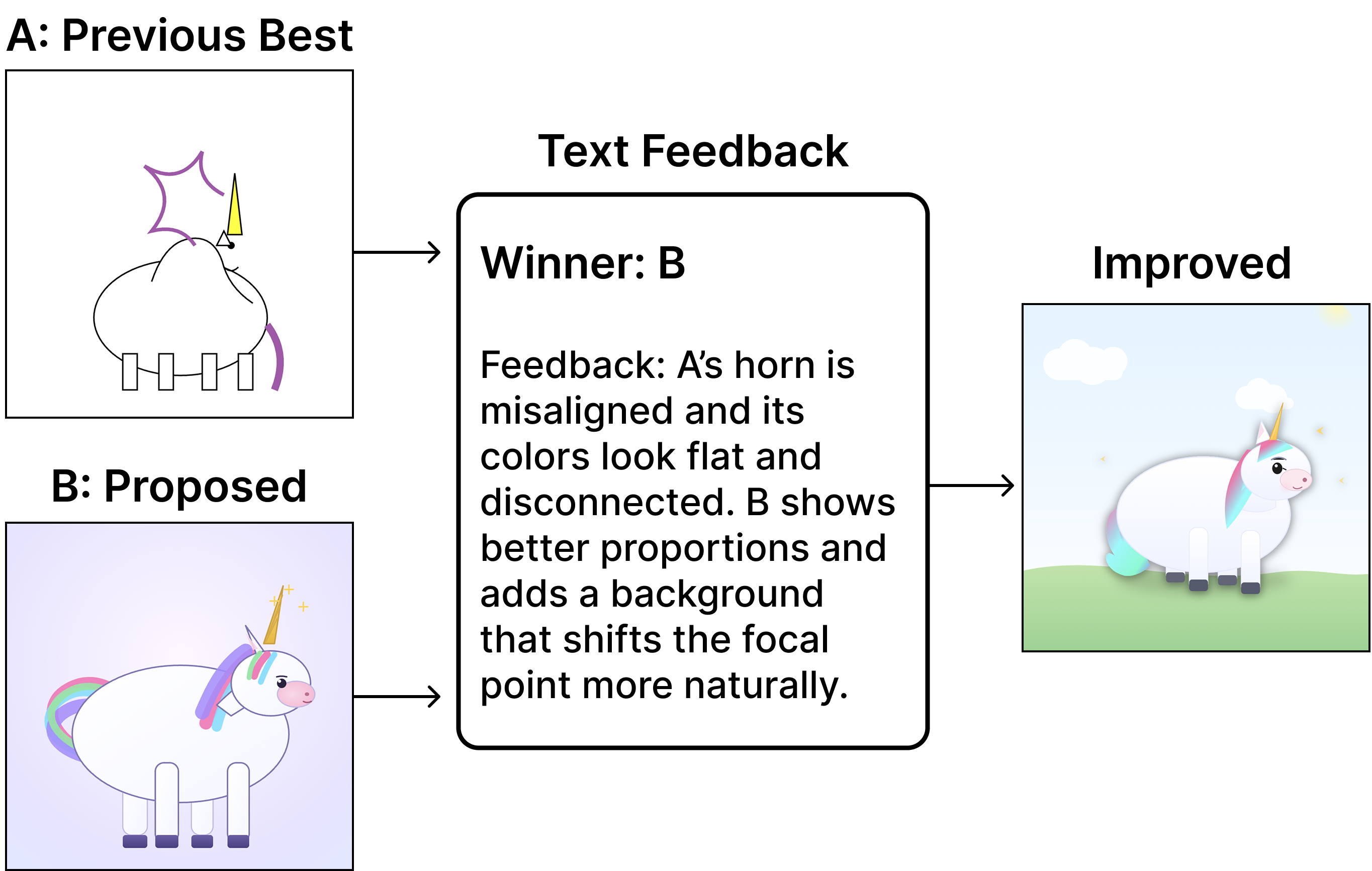
Following the Text Gradient at Scale
RL Throws Away Almost Everything Evaluators Have to Say


T*: Rethinking Temporal Search for Long-Form Video Understanding
Most video understanding models drown in data at inference time. Imagine watching a 60-minute security video just to answer: “Who…

