markdown
# **Securing Your RAG Pipeline: Why Trusting the LLM Isn’t Enough**
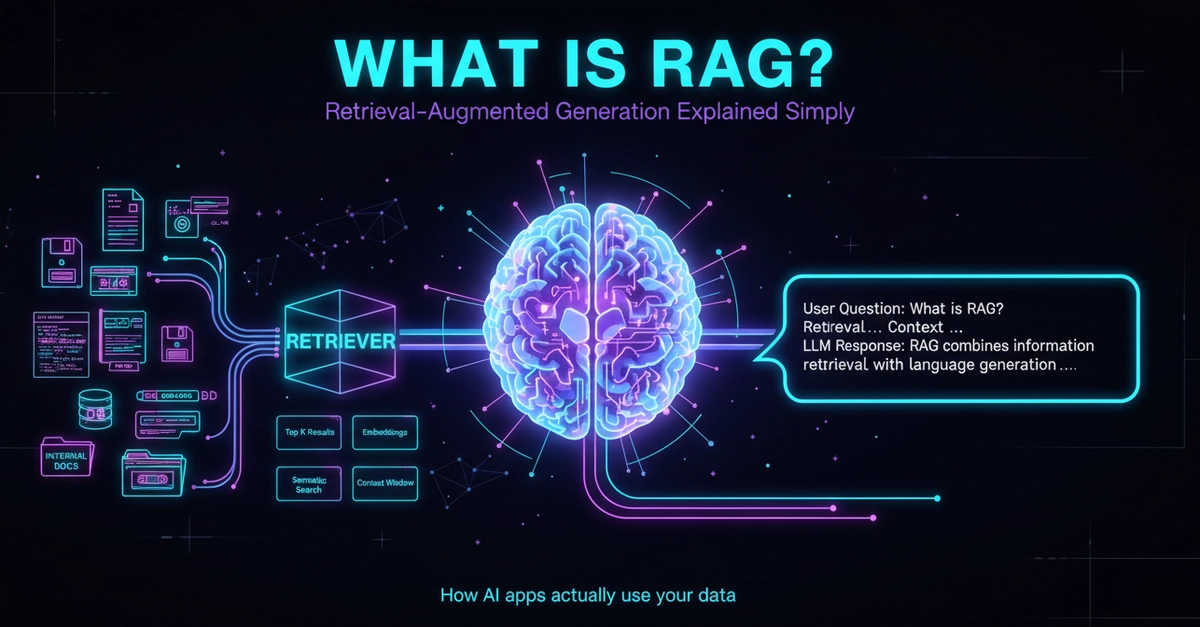
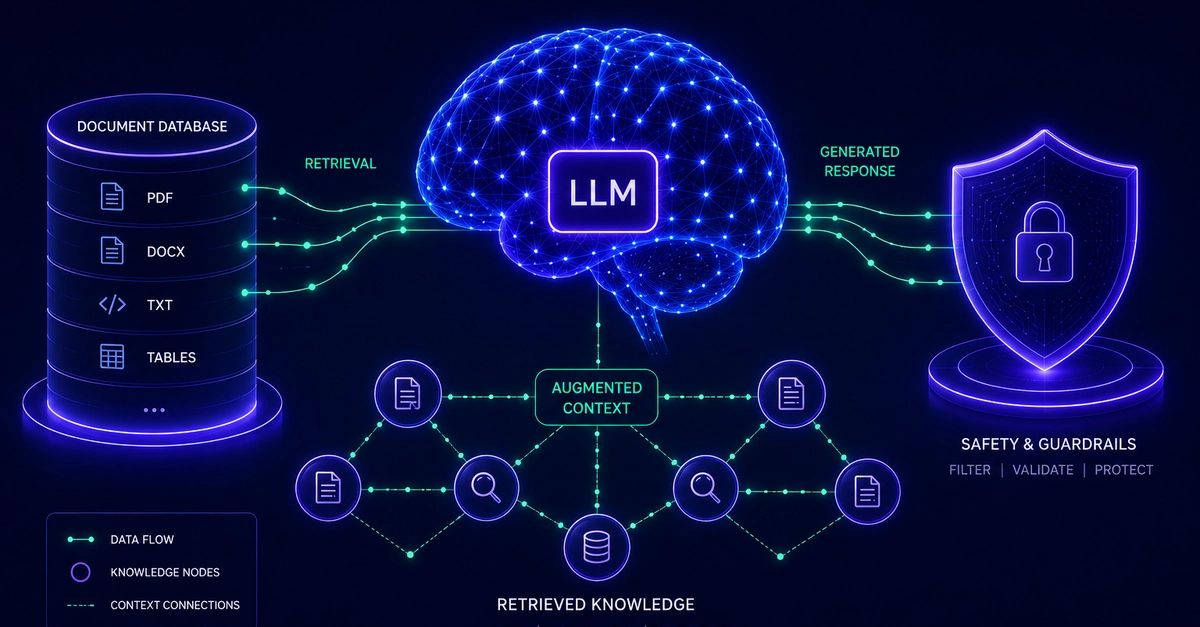
Retrieval-Augmented Generation (RAG) promises to turn static LLMs into dynamic, knowledge-powered systems—but this capability comes with a hidden cost. By connecting LLMs to live data sources, RAG expands the attack surface exponentially, introducing risks like data poisoning, indirect prompt injection, and unintended data leaks. The problem? Most security strategies still treat RAG as an extension of LLM security, ignoring the unique vulnerabilities introduced at every stage of the pipeline. The result? A false sense of protection where the most critical threats go unchecked.
To secure RAG effectively, enterprises must adopt a **defense-in-depth** approach—layering controls across input, storage, retrieval, and generation—not just relying on the LLM’s built-in safeguards. The stakes are high: research shows that just **five poisoned documents** in a knowledge base of millions can manipulate outputs with **90% success**, while embedding inversion attacks can recover **50-70% of original text** from compromised vectors. The question isn’t *if* RAG will be targeted, but *when*—and whether your defenses will hold.