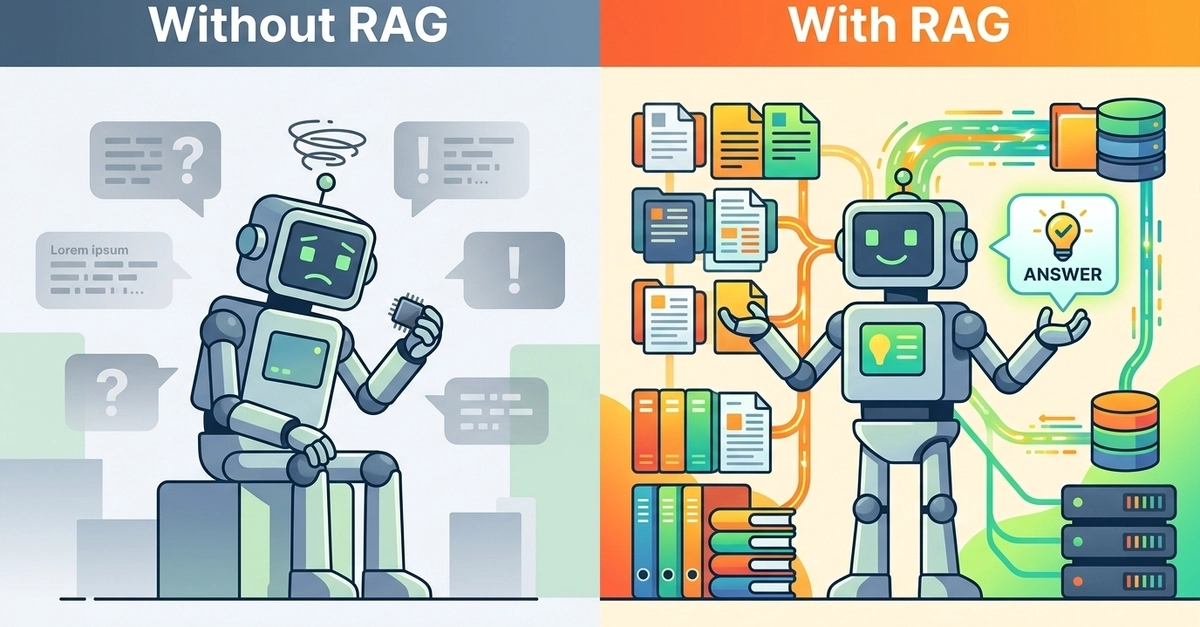
Ask a large language model for a specific statistic, then ask where it found that number. More often than not, the citation it gives you doesn't exist. The model will hallucinate a plausible-looking reference, confidently present outdated conclusions, or simply make things up without any internal signal that something is wrong. This failure mode has a well-known name — hallucination — and the most widely adopted engineering solution for it is RAG.
RAG in One Sentence
RAG stands for Retrieval-Augmented Generation. The idea is straightforward: before the LLM generates an answer, retrieve relevant document chunks from an external knowledge base, then feed those chunks to the model as context so it can compose its response based on real source material rather than parametric memory alone.
Think of it like writing a research paper. You don't cite statistics from memory; you look them up first, then write your argument around verified data. RAG gives language models the same "look it up, then write" workflow.
Three Structural Limitations of LLMs