I once submitted an essay with three citations that I hadn't personally verified. The AI had suggested them, and they sounded right.
None of them existed.
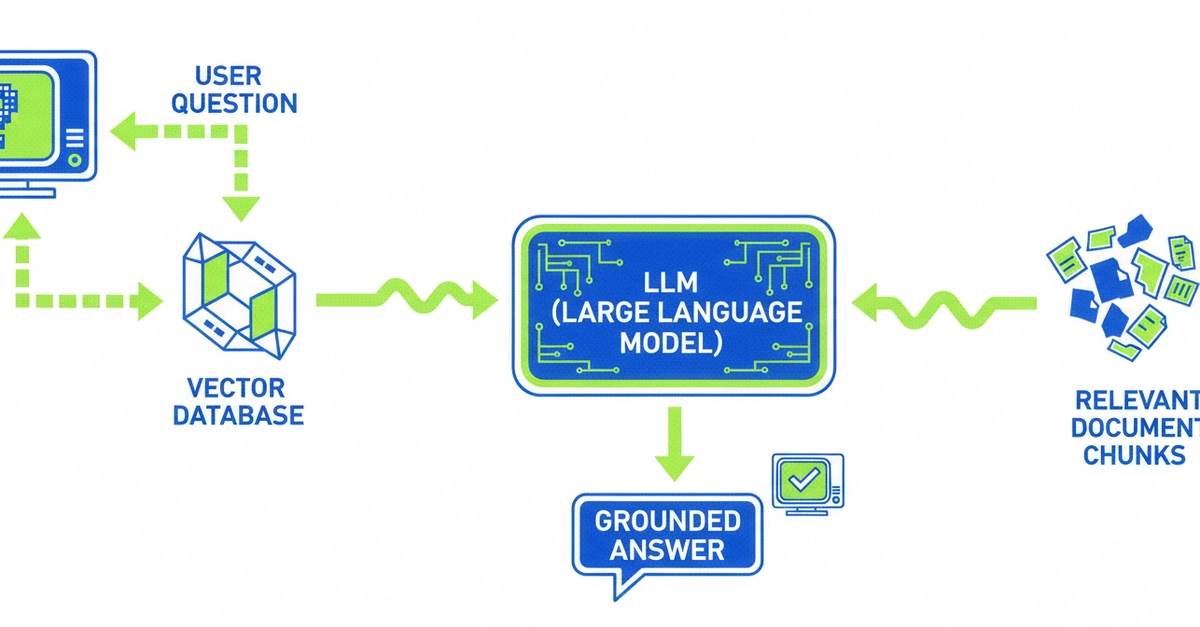
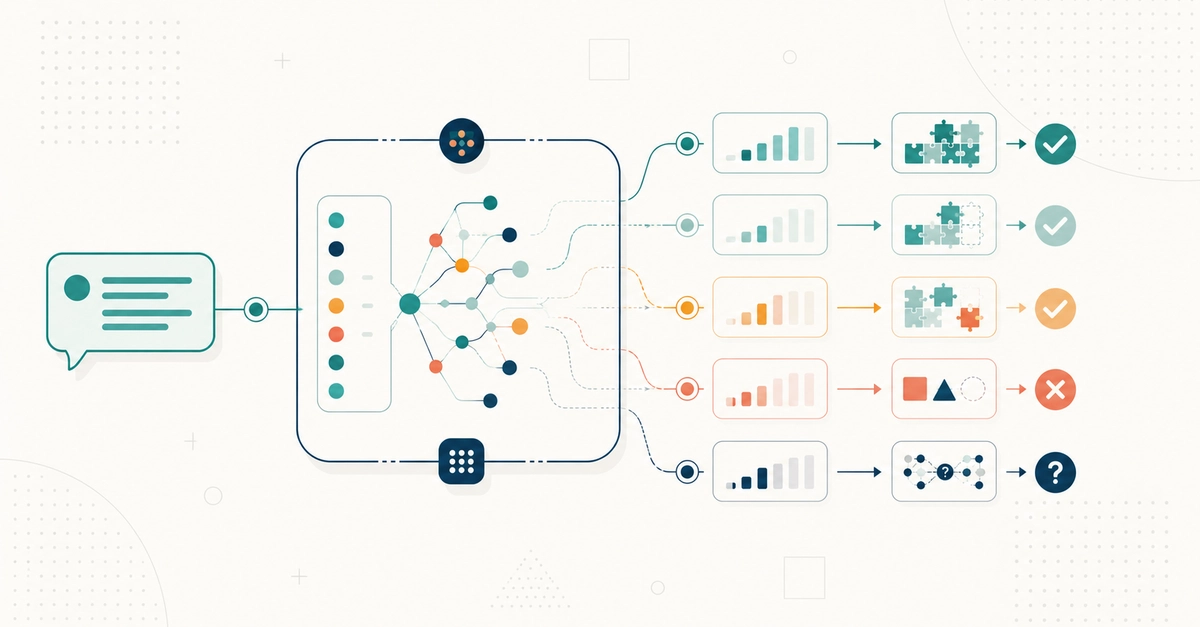
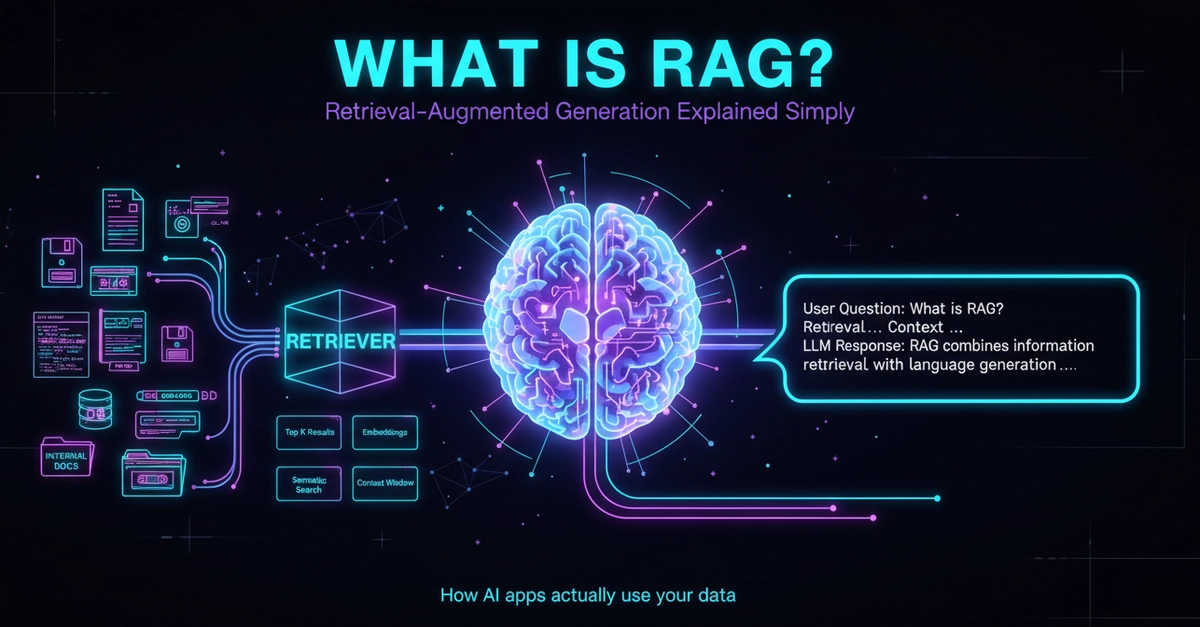
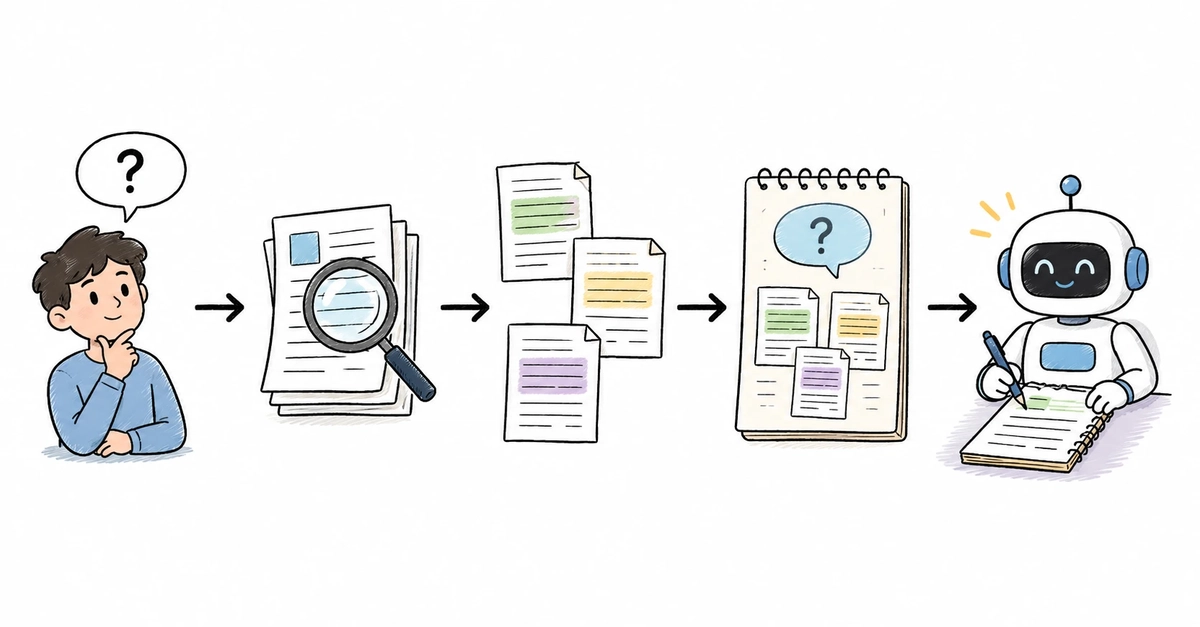
That's not a quirk or a bug — it's exactly how LLMs work. And once you understand why, a technique called RAG starts to make a lot of sense.
AI assistants are remarkably good at sounding right. The model isn't lying — it's doing its best with what it knows. The problem is that what it knows has limits, and it doesn't always know where those limits are. Ask one about a recent event, a niche regulation, or anything from a source it's never seen — and it fills the gap anyway. Confidently.
That's the gap RAG was built to close. Once you understand how it works, you'll have a much clearer picture of why some AI tools are genuinely reliable and others are just very convincing guessers.