A machine learning model that performs well on day one will not remain stable by default. Performance can degrade over time due to data drift, changes in user behavior, evolving feature sets, or updates to upstream systems. These changes rarely cause immediate failure, but they reduce reliability and make model behavior harder to understand.
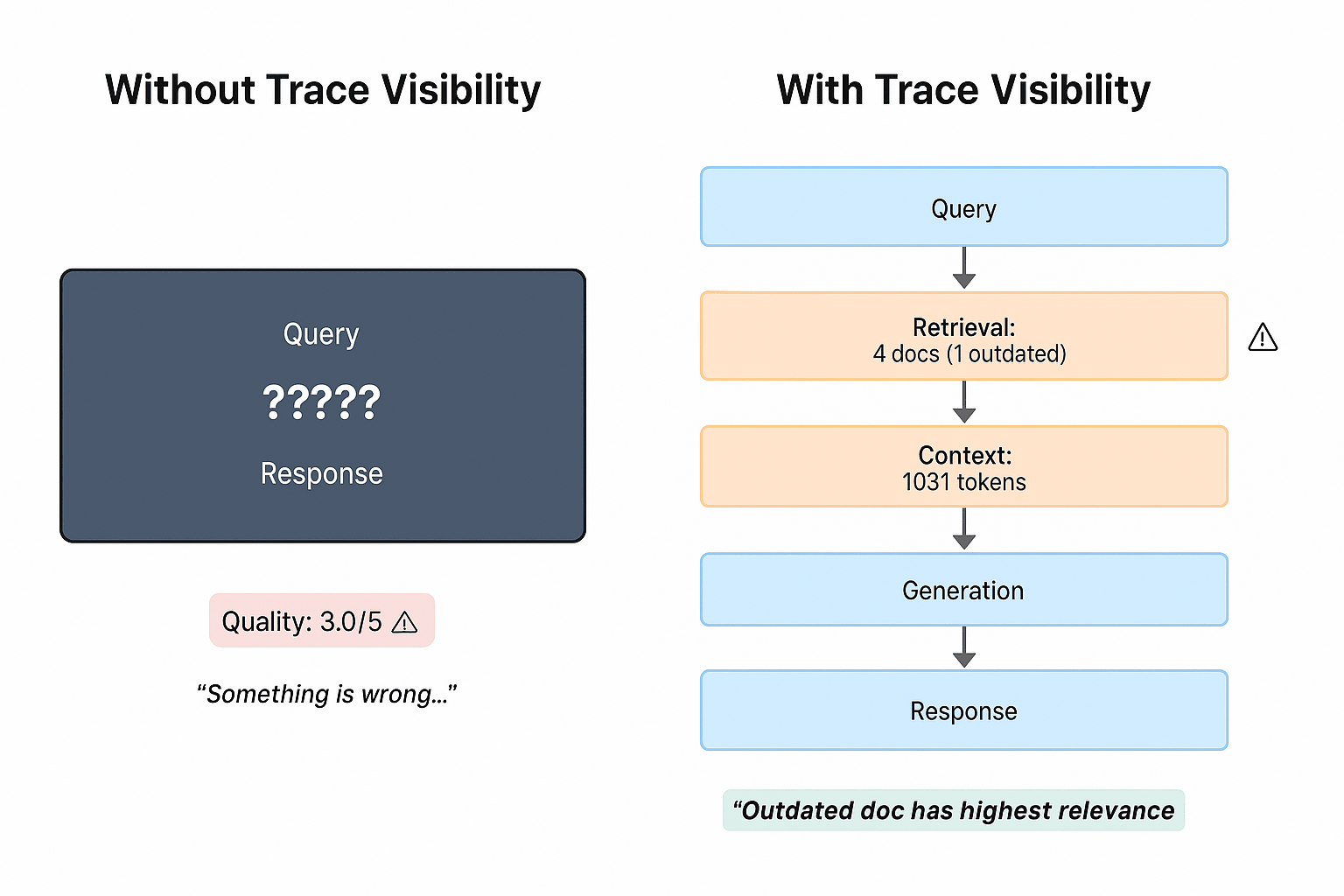
The core issue is not model quality, but a lack of coordination across the lifecycle. Decisions made early in the lifecycle affect every stage that follows. When stages operate in isolation, traceability breaks down. For example, code versioning may capture model changes, but not dataset lineage, feature definitions, or runtime behavior.
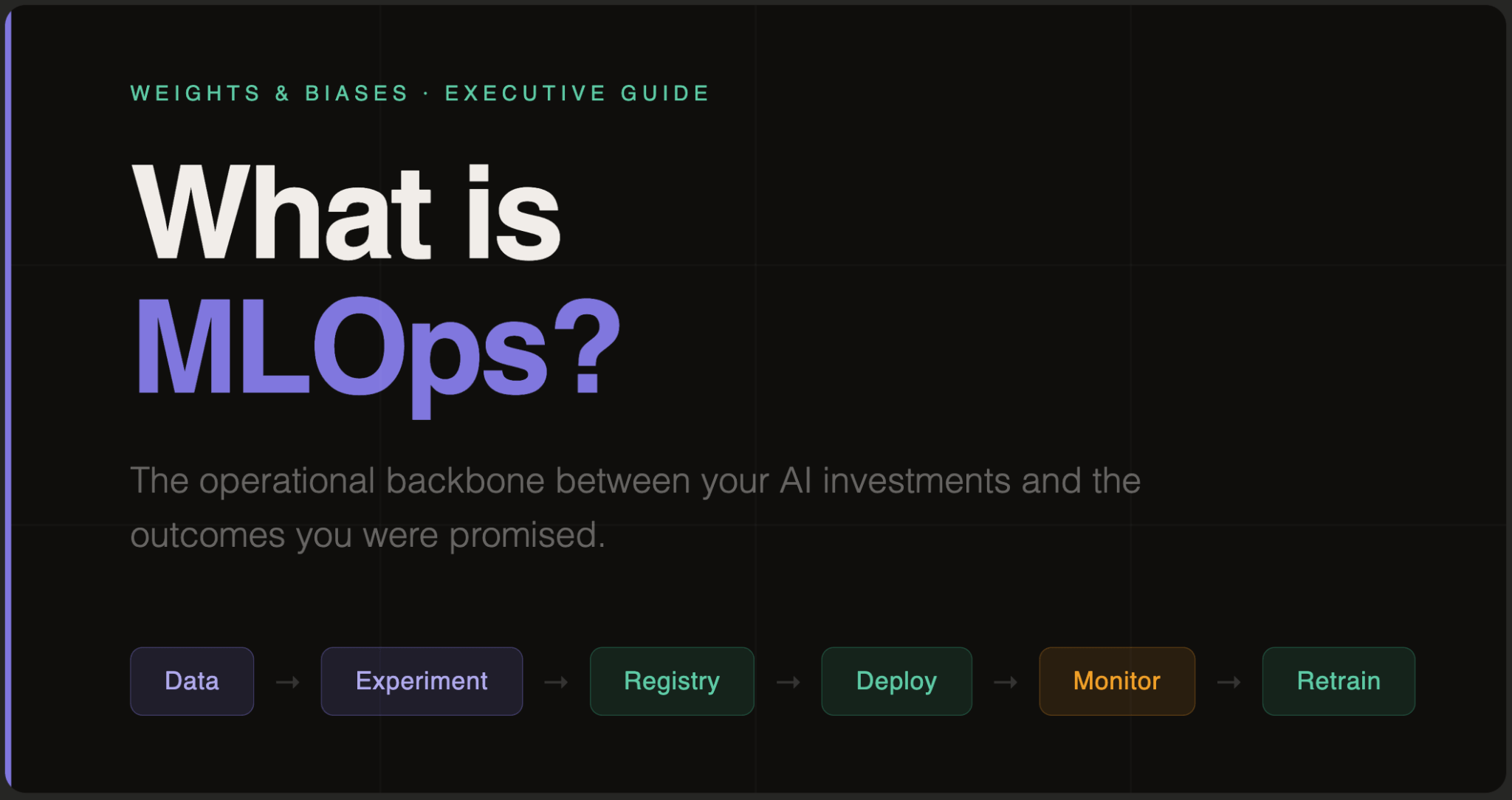
MLOps addresses this by treating machine learning as a continuous, end-to-end lifecycle. It connects data, features, training, deployment, monitoring, and governance into a single operating model. Each stage introduces its own assumptions and dependencies, from training and validation to deployment, monitoring, and governance.
Summary of key MLOps lifecycle concepts
Stage