Lambda has always been one request at a time per execution environment. Your function starts, processes a single invocation, and sits idle until the next one arrives. If you need to handle a thousand concurrent requests, Lambda spins up a thousand execution environments - each with its own memory, its own cold start, and its own per-GB-second bill.
Lambda Managed Instances changes that model. Announced at re:Invent 2025 and expanded with 32 GB memory / 16 vCPU support in March 2026, LMI runs your functions on EC2 instances in your VPC with AWS handling provisioning, patching, scaling, and load balancing. Each execution environment handles multiple concurrent requests. You keep the Lambda programming model and gain EC2 hardware selection and pricing.
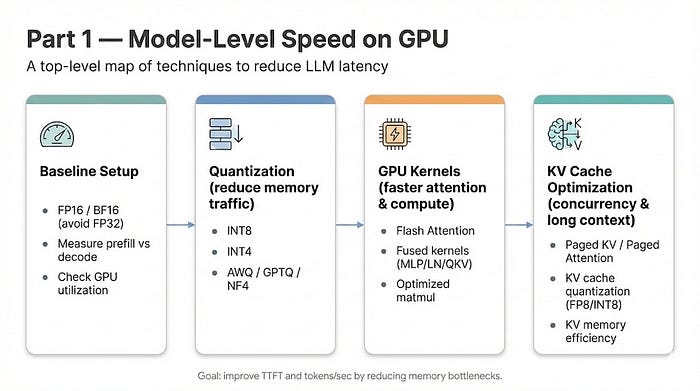
I built a product similarity engine to explore how this works in practice. The handler loads a product catalog with Nova embeddings via Bedrock into memory, uses Amazon Nova Multimodal Embeddings to embed incoming search queries, and computes cosine similarity across categories in parallel using ThreadPoolExecutor. It's the kind of workload that doesn't fit well on standard Lambda - sustained throughput, memory-intensive, with a mix of I/O (Bedrock API calls) and CPU (vector math) that benefits from multi-concurrency and configurable memory-to-vCPU ratios. The project uses Terraform for infrastructure, Python 3.14 with Powertools for observability, and the embedding model is configurable (Nova by default, Titan Text Embeddings V2 as an alternative).