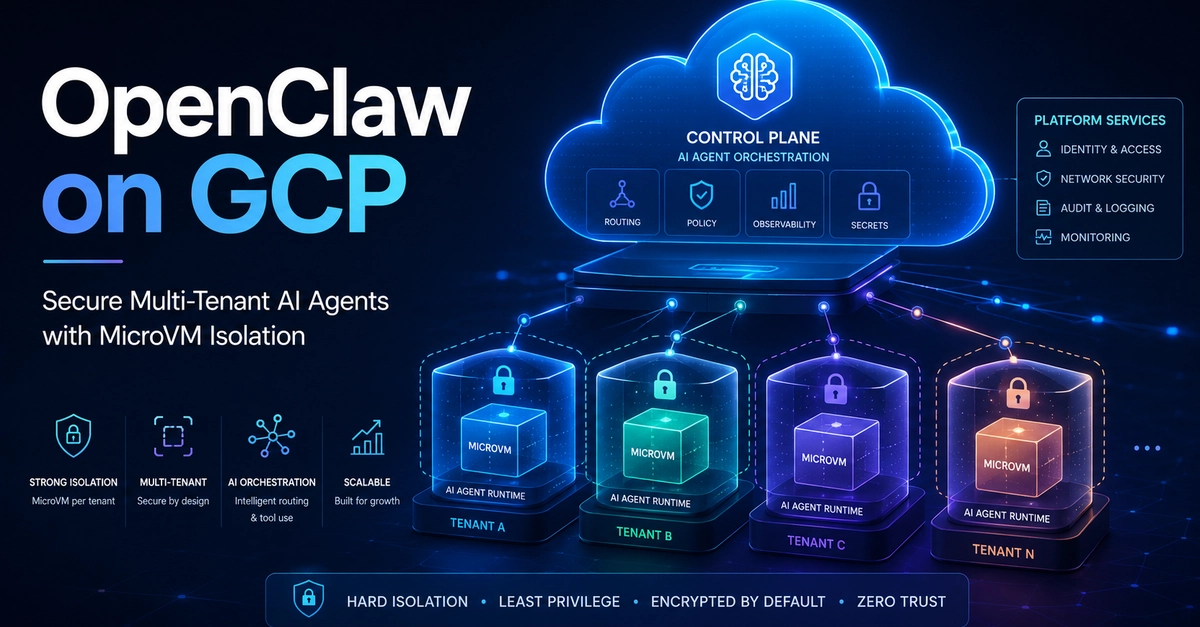
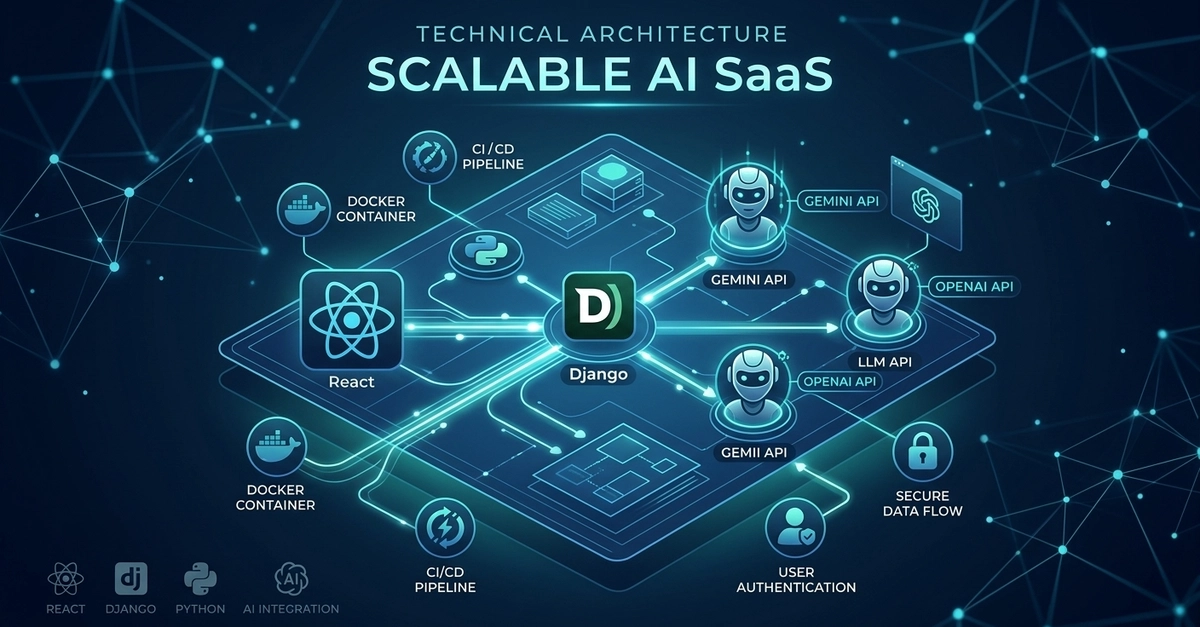
In early 2023, Slack faced a foundational challenge: serving Large Language Models (LLMs) at enterprise scale with the security, reliability, and performance our customers expect. Over three years, we evolved from basic infrastructure to orchestrating a sophisticated multi-cloud architecture. We didn’t just want shiny new models; we needed a system resilient to regional outages and GPU scarcity. Our journey moved through four distinct phases, shifting from reactive infrastructure management to proactive, multi-vendor orchestration.
Phase 1: The SageMaker Era
When we built the initial stages of Slack AI, AWS SageMaker was the natural starting point. It was a managed ML Serving platform that offered the key things that we were looking for: Security, FedRamp compliance, model availability and control. We were able to leverage a sophisticated escrow virtual private cloud (VPC) strategy to establish a strict zero-knowledge environment: our data remained private to Slack, and the provider’s proprietary model weights remained inaccessible to us.
To maximize uptime for a global user base, we deployed these containers across multiple AWS regions. This required our teams to manage the operational lifecycle, including cross-region IAM roles, balanced routing across model endpoints, proactive capacity planning, and auto-scaling logic.