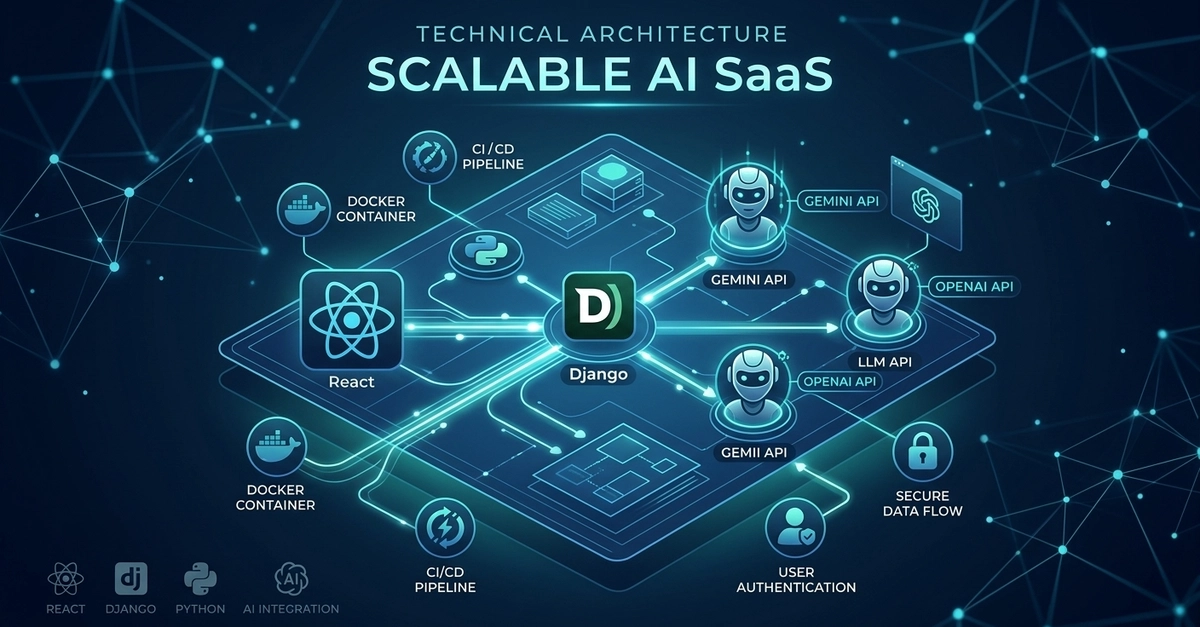
The integration of Large Language Models (LLMs) into modern web applications has shifted from a novelty to a necessity. However, moving from a simple API wrapper to a production-ready, highly scalable AI SaaS platform presents unique architectural challenges. It requires a delicate balance between real-time frontend responsiveness and heavy, asynchronous backend processing.
When architecting AI-driven platforms, I rely on a decoupled stack: React (or Next.js) for the presentation layer and Django (Python) for the backend microservices. This separation of concerns is crucial when dealing with agentic workflows and unpredictable LLM response latencies.
Handling the Frontend State with React
AI interactions, unlike standard database queries, are rarely instantaneous. Users expect fluid, streaming responses akin to modern chat interfaces. By leveraging Next.js alongside advanced React state management, we can implement server-sent events (SSE) or WebSockets. This allows the frontend to render token-by-token streams without blocking the main thread, keeping the UI highly interactive while the AI model computes in the background.
Robust Orchestration with Django






