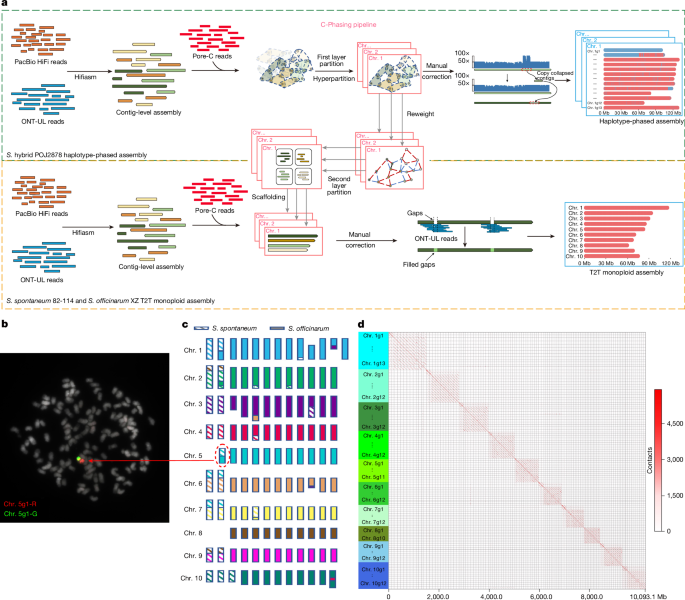
MainIt is hard to imagine a world without readily available sweet treats, but that was the reality before sugarcane was domesticated. Early humans depended on scarce and seasonal sources of sweetness, such as honey, which were considered luxuries. The domestication of sugarcane revolutionized sugar production, transforming it into a global dietary staple. However, this transformation came with profound costs: widespread availability and overconsumption of sugar have contributed to a global health crisis, and the expansion of sugar production was deeply intertwined with the transatlantic slave trade, which reshaped human migration, cultures and economies at the global scale.Sugarcane is the world’s leading sugar crop, renowned for its exceptional ability to accumulate sucrose in stalk parenchyma cells. However, the genetic mechanisms underlying this trait remain largely unexplored. Evidence in other crops suggests a strong association between parenchyma cell size and sugar accumulation. For example, in sugar beet (Beta vulgaris), BZR1 promotes parenchyma cell expansion, enhancing sugar loading efficiency2, and, in strawberry (Fragaria vesca), the tonoplast transporter MATE51 coordinates sugar transport with cell size3. In sugarcane, modifications in parenchyma cell wall elasticity allow cells to withstand high turgor pressure from sucrose accumulation4. Nevertheless, the specific genes and regulatory networks governing these processes in sugarcane remain unclear, limiting our understanding of its exceptional productivity as a sugar crop.Modern sugarcane improvement has been shaped by hybridization between Saccharum officinarum and Saccharum spontaneum, followed by repeated backcrossing with S. officinarum—a process known as nobilization1. Together with evidence for an unknown Saccharum contributor in early hybridization5, these processes have merged divergent Saccharum lineages, resulting in extreme polyploidy and genomic complexity. The evolutionary history has left genome-wide signatures of introgression, identity-by-descent (IBD) from founder cultivars, and selective sweeps associated with domestication and modern breeding. Although challenging, dissecting these signatures using haplotype-resolved references and allele-aware analyses offers a promising path to unravelling the considerable adaptability and productivity of sugarcane.Advances in long-read sequencing technologies, such as PacBio HiFi and BioNano, have proven to be effective in resolving polyploid genomes, as demonstrated by recent assemblies for hybrid cultivars6,7,8,9. However, gaps remain in achieving full haplotype-level resolution, understanding allele-specific expression and deciphering the molecular mechanisms that drive high sugar capacity. Short-read sequencing, despite aiding high-throughput chromosome conformation capture (Hi-C) and RNA-sequencing (RNA-seq) applications, struggles to resolve homologous or homoeologous sequences, leading to errors in haplotype phasing and allelic expression analyses10,11.Emerging long-read technologies—Oxford Nanopore Technologies Ultra-Long (ONT-UL) reads, Pore-C sequencing12 and multiplexed arrays isoform sequencing (MAS-ISO-seq)13—offer possibilities for accurate genome assembly and allelic resolution. Yet, their application to sugarcane’s ultra-complex genome has been limited by the absence of tailored bioinformatics tools. Here we integrate C-Phasing (a haplotype-resolved assembly algorithm14), KMERIA (a polyploid genome-wide association study (GWAS) tool15) and Allele-Express (an allele-specific expression tool) to generate a fully phased genome for the hybrid cultivar POJ2878. By resequencing 981 Saccharum accessions, we traced sugarcane’s domestication and improvement, identifying key genetic shifts and loci associated with sugar storage. This work illuminates sugarcane’s molecular evolution and establishes a robust framework for polyploid genomics, positioned to accelerate breeding in sugarcane and other crops with complex genomes.A fully phased genome assemblyThe POJ2878 cultivar, known as the ‘King of sugarcane’, was selected for de novo genome sequencing and assembly due to its role as a key genetic donor for modern sugarcane cultivars. A high-quality genome assembly was generated using advanced sequencing technologies, including 678.52 Gb of MGI-seq short reads, 405.42 Gb of PacBio HiFi reads and 148.64 Gb of ONT-UL reads with N50 lengths over 100 kb (Supplementary Table 1). The average read lengths are 15.84 kb (PacBio) and 161.94 kb (ONT-UL) (Supplementary Fig. 2). Pore-C technology, an ONT-based method capturing high-order chromatin 3D structure, produced 517.13 Gb of reads with 2.60 kb average length and 4.15 kb N50. Notably, 15.15% of Pore-C reads (22.31 million out of 147.25 million) contained at least three chromatin concatemers (Supplementary Table 2 and Supplementary Fig. 3). Together, these datasets provided 376× coverage of the estimated 10-Gb genome. Hifiasm was used with the HiFi and ONT-UL reads to yield a 10.37-Gb contig-level assembly with a 15.60-Mb N50 (Extended Data Table 1 and Supplementary Table 3).The C-Phasing algorithm14, integrating Pore-C long-range contact information, was used to achieve a fully haplotype-resolved, chromosomal-scale genome assembly (Fig. 1a). Pore-C technology substantially improved the proportion of uniquely aligned reads (75.30% versus 39.81%), and the rate of valid interaction pairs (36.44% versus 29.69%; Supplementary Table 2), producing a clearer chromatin interaction heat map than Hi-C technology (Supplementary Fig. 4). Using a hyperpartition algorithm, C-Phasing resolved 118 groups, each representing one chromosome (Extended Data Table 1), matching the karyotype determined using fluorescence in situ hybridization (FISH) (Fig. 1b). After manual correction, the final assembly comprises 10 homologous/homoeologous groups, each containing an average of 12 chromosomes (Fig. 1c).Fig. 1: Genome assembly, subgenome identification and chromosomal rearrangement.The alternative text for this image may have been generated using AI.Full size imagea, Schematic of the pipeline used to generate a haplotype-resolved genome assembly for the Saccharum hybrid cultivar POJ2878 and T2T monoploid genome assemblies for the progenitor species, S. spontaneum 82-114 and S. officinarum XZ. The genomes were sequenced using the PacBio HiFi, ONT-UL and Pore-C sequencing technologies. For POJ2878, phased unitigs (p_utg) assembled by hifiasm were partitioned into homologous or homoeologous groups and haplotypes using C-Phasing with Pore-C contacts, and collapsed regions were recovered based on sequencing depth to produce a fully haplotype-resolved assembly. For the progenitor T2T monoploid assemblies, hifiasm contigs (p_ctg) were deduplicated, scaffolded into monoploid chromosomes using C-Phasing and gap-filled with ONT-UL reads. b, Oligonucleotide painting (oligo-FISH) of chromosome (chr.) 5g1 using two probe sets (chromosome 5g1-R and chromosome 5g1-G) labelling S. spontaneum-derived (red; 1.56–42 Mb) and S. officinarum-derived (green; 42–81.72 Mb) segments, respectively. The image is representative of one metaphase cell from one POJ2878 plant. c, A proposed model of chromosomal rearrangement based on subgenome assignments and synteny analysis. Different colours represent distinct homologous or homoeologous groups; the shaded rectangles indicate S. spontaneum-derived sequences and the filled rectangles represent S. officinarum-derived sequences. d, Raw chromatin interactions among the 118 chromosomes, highlighting intrachromosomal and interchromosomal interactions.The genome assembly quality was assessed across three dimensions: completeness, contiguity and accuracy (Supplementary Note 1 and Supplementary Table 4). Notably, the assembly demonstrated a high level of contiguity, achieving a contig N50 of 15.60 Mb, along with extremely low error rates, including 2.02% switched and 0.82% collapsed genomic regions (Supplementary Fig. 5). Chromatin contacts showed stronger intrasubgenome interactions than intersubgenome interactions (Fig. 1d). These results highlight the high quality of the POJ2878 genome assembly, with most evaluation metrics meeting or exceeding those of previously published hybrid sugarcane genomes.Recombination and rearrangementThe genomic components of POJ2878 was analysed using resequencing data from 10 S. officinarum and 10 S. spontaneum individuals (Methods). This analysis revealed that 80.5% (8.35 Gb) of the genome originated from S. officinarum and 19.5% (2.02 Gb) from S. spontaneum (Supplementary Fig. 6). We further identified marked recombination events between the S. officinarum and S. spontaneum subgenomes, with recombined regions constituting at least 10% of their length. This classified the genome into 92 S. officinarum-derived, 16 S. spontaneum-derived and 10 recombinant chromosomes (Extended Data Fig. 1a and Supplementary Table 5).We identified 13.23 Mb of small-scale homoeologous exchanges distributed across 49 S. officinarum-derived and 2 S. spontaneum-derived chromosomes, representing 0.13% of the genome (Supplementary Table 5) and encompassing 320 protein-coding genes (11 S. officinarum and 309 S. spontaneum derived). Functional analysis showed that S. officinarum-derived genes were enriched in processes such as stimulus response and intracellular signal transduction, whereas S. spontaneum-derived genes were enriched in post-embryonic development and system development (Fisher’s exact test, P < 0.05; Supplementary Fig. 7).To investigate chromosomal rearrangements, we generated telomere-to-telomere (T2T) monoploid genome assemblies for the progenitor species S. officinarum XZ and S. spontaneum 82-114 (Supplementary Note 2). Synteny analysis revealed high overall collinearity and frequent non-homologous chromosomal rearrangements in POJ2878 (Extended Data Fig. 1), including confirmed chromosome fission and fusion events in S. spontaneum-derived subgenome16 and four large-scale non-homologous rearrangements in the S. officinarum-derived subgenome. Notably, chromosome 5g1 resulted from a crossover, with its first 42 Mb derived from the S. spontaneum subgenome and the rest from the S. officinarum-derived subgenome. This structure was independently validated using haplotype-specific probes in oligo-FISH experiments (Fig. 1b), confirming the recombination event and assembly accuracy.Telomeric analysis revealed that all 118 chromosomes had at least one telomere annotated, with 73 (61.86%) chromosomes containing telomeres at both ends (Extended Data Fig. 2 and Supplementary Table 6). Centromeric analysis identified 14 telocentric, 6 acrocentric, 33 submetacentric and 65 metacentric regions with averaging 2.22 Mb. Notably, 40% of the 10 S. spontaneum–S. officinarum recombined chromosomes were telocentric and acrocentric.Haplotype-specific gene expressionThe POJ2878 genome is composed of 69.24% (7.18/10.37) transposable elements with long terminal repeat (LTR) retrotransposons being the predominant class in both subgenomes (52.04% in the S. spontaneum subgenome and 59.05% in the S. officinarum subgenome; Supplementary Table 7 and Supplementary Fig. 8a). Both values exceed the proportions observed in the progenitor genomes, with 41.36% in S. spontaneum 82-441 and 49.48% in S. officinarum XZ. This elevated LTR content reflects lineage-specific LTR bursts, occurring around 0.16 million years ago in the S. officinarum-derived subgenome and around 0.2 million years ago in the S. spontaneum subgenome (Supplementary Fig. 8b), predating POJ2878’s hybridization events less than 120 years ago. These results suggest that the actual progenitors used in producing POJ2878 differ from those analysed here.A comprehensive annotation pipeline initially identified 398,858 protein-coding genes (including allelic genes), followed by classification of genes with defined alleles, paralogous genes and haplotype-specific genes (Methods and Extended Data Fig. 3). This produced a high-quality allele-defined annotation with 98.6% BUSCO completeness (Supplementary Table 8), encompassing 35,082 and 28,851 genes in the S. officinarum- and S. spontaneum-derived subgenomes, respectively (Extended Data Table 1 and Supplementary Table 9). These allele-defined genes represent instances in which multiple allelic variants are present within the genome, with each allele differing by at least one nucleotide variant in coding sequences. A total of 28,523 homoeologous gene pairs were identified between the two subgenomes.Quantifying haplotype-specific gene expression in polyploid genomes is challenging due to the inability of short RNA-seq reads to accurately distinguish highly similar haplotypes. To address this, we used MAS-ISO-seq13, which captures full-length transcripts by ligating multiple cDNA fragments into single molecules, and developed Allele-Express, specifically designed to improve allele-specific expression analysis in polyploids (Extended Data Fig. 4). Benchmarking showed that Allele-Express achieved higher accuracy compared with RNA-seq methods (R2 = 0.95 versus R2 = 0.70; Supplementary Note 3).Using MAS-ISO-seq and Allele-Express, we sequenced transcripts from mature leaf and stem tissues, generating 63.88 million and 56.23 million full-length transcripts, respectively (Supplementary Table 10). Each replicate yielded an average of 30.75 Gb (leaf, 1,444 bp mean length) and 27.83 Gb (stem, 1,476 bp mean length), with replicates showing high consistency (Pearson correlation > 0.98; Supplementary Fig. 9). A saturation curve showed that transcript discovery plateaued beyond 18 Gb (30× transcriptome coverage; estimated transcriptome size: 616.78 Mb; Supplementary Fig. 10). We identified 6,994 allele-specific highly expressed genes (ASHEGs) in mature stem and 7,325 in mature leaf samples, where one allele was significantly more highly expressed than its counterparts (G-test, P < 0.05). ASHEGs were unevenly distributed across chromosomes, with significant enrichment observed on five chromosomes in stem tissue and nine in leaf tissue (binomial test with Bonferroni correction, adjusted P < 0.01; Supplementary Fig. 11a,b). This enrichment followed tissue-specific chromosomal activation patterns, with seven out of ten enriched chromosomes originating from the S. spontaneum subgenome and only three from the S. officinarum-derived subgenome. The S. spontaneum subgenome displayed significantly higher ASHEG density than the S. officinarum-derived subgenome in both stem (0.024 versus 0.016, Mann–Whitney U-test, P < 0.001) and leaf (0.026 versus 0.017, P < 0.001) tissues (Supplementary Fig. 11c,d), despite comprising only approximately 20% of the POJ2878 genome. This indicates a disproportionate contribution of S. spontaneum-derived alleles to allele-specific high expression.Functional enrichment analysis revealed that these ASHEGs were associated with critical biological processes and cellular components (Supplementary Figs. 12 and 13). In leaf, ten ASHEGs were enriched in cotyledon morphogenesis, and seven in the positive regulation of auxin-mediated signalling pathways, including genes such as PIN1 (auxin transport17) and CSA-like transcription factors (regulating sugar content18; Supplementary Fig. 14). In stem tissue, ASHEGs were enriched in storage vacuoles (18 genes) and COPI-coated vesicles (9 genes; Supplementary Fig. 15), with examples including the probable aquaporins TIP2 and TIP3 (cell turgor pressure and cell expansion19) and beta-COP1 (light signalling regulation20).Resequencing and population structureWe resequenced 981 Saccharum samples, including 78 S. officinarum, 290 S. spontaneum and 613 hybrid sugarcane cultivars, representing 19 major sugarcane-producing regions worldwide (Fig. 2a–c). This generated 125.58 Tb of short-read data with an average depth of 16.57× per sample (Supplementary Table 11). Analysis of uniquely aligned reads to the POJ2878 reference genome yielded 11.43 million single-nucleotide polymorphisms (SNPs) and 7.36 million insertion–deletions (indels). Phylogenetic analysis using high-quality SNPs revealed three distinct clades (S. spontaneum, S. officinarum and hybrids), supported by population structure analyses (admixture and principal component analysis (PCA)), which also highlighted extensive genetic admixture among hybrids (Fig. 2d,e).Fig. 2: Genetic diversity and population structure analysis.The alternative text for this image may have been generated using AI.Full size imagea–c, The geographical distribution of S. spontaneum (S. s.) (a; n = 290), hybrid cultivars (S. hybrid) (b; n = 613) and S. officinarum (S. o.) (c; n = 78), showcasing the global representation of the sampled accessions. The base map was generated using the R package rnaturalearth with data from Natural Earth (http://naturalearthdata.com). d, Phylogenetic tree and admixture analysis (k = 3) of the resequenced accessions, illustrating the genetic relationships and levels of admixture among S. spontaneum, S. officinarum and hybrid populations. e, PCA of S. spontaneum, S. officinarum and hybrid accessions, highlighting the genetic differentiation and clustering of the three populations. f, The genome-wide mean nucleotide diversity (π) within each population and population fixation statistics (FST) between different populations, revealing the genetic diversity and differentiation among S. spontaneum, S. officinarum and hybrids. g, Linkage disequilibrium decay patterns across the three populations; linkage disequilibrium was measured as r2 and plotted against physical distance (kb), showing the population-specific difference in linkage disequilibrium decay rates.Source dataSaccharum spontaneum exhibited higher nucleotide diversity (π = 1.28 × 10−4) than S. officinarum (π = 2.43 × 10−5), reflecting its broader natural distribution (Fig. 2f), and hybrid sugarcane showed diversity (π = 1.27 × 10−4) similar to its S. spontaneum progenitor, probably due to diverse wild germplasm and gene flow. The population differentiation statistic between S. spontaneum and S. officinarum (FST = 0.20) is higher than that between S. spontaneum and hybrids (FST = 0.12), or between S. officinarum and hybrids (FST = 0.08). Moreover, S. spontaneum showed a more rapid decay of linkage disequilibrium, probably reflecting its larger effective population size (Fig. 2g).POJ2878 shaping modern breedingTo access the genetic contribution of POJ2878 to modern sugarcane cultivars, we analysed 573 geographically diverse samples (327 Chinese, 246 non-Chinese). IBD analysis revealed that 95.3% cultivars shared over 821.6 Mb of IBD sequences with POJ2878, underscoring the extensive use in global sugarcane breeding programmes (Fig. 3a). Genome-wide analysis showed that 98.15% of the genome exhibited introgression from POJ2878 (Fig. 3b), with the top 5% of IBD-dense regions spanning 474.70 Mb. These regions contained 28,308 protein-coding allelic or homoeologous genes, representing haplotypes favoured by breeders. These genes were significantly enriched in important biological processes, including starch and sucrose metabolism and environmental adaptation (Fisher’s exact test, P < 0.05; Supplementary Fig. 16). Key genes included sucrose synthase (SUS), sucrose-phosphate phosphatase (SPP), sucrose phosphate synthase (SPS)21 and sucrose transporters (SWEET14, SWEET15 and SUT) (Fig. 3c). Allele-specific gene expression analysis further revealed that many of these favourable haplotypes exhibited expression in stem and/or leaf tissues (Fig. 3d). However, their expression was not always the highest or lowest among the alleles, consistent with previous observation22. This pattern suggests that alternative haplotypes may still hold untapped potential for future improvement.Fig. 3: The genetic contribution of POJ2878 and analysis of breeder-favoured haplotypes.The alternative text for this image may have been generated using AI.Full size imagea, Empirical cumulative distribution of total IBD length shared between 573 sugarcane cultivars and POJ2878. The x axis shows the total IBD length per cultivar (Mb), and the y axis shows the percentage of cultivars. The dashed line at 821.6 Mb indicates that 95.3% of cultivars share at least 821.6 Mb of IBD sequence with POJ2878. b, The IBD density in 50-kb non-overlapping genomic windows across global (n = 573), Chinese (n = 327) and non-Chinese (n = 246) population cultivars. Statistical analysis was performed using two-sided Mann–Whitney U-tests; ***P < 0.001. The violin plot width reflects the frequency of windows; the white dots show the average IBD density; the box indicates the interquartile range (IQR; 25th–75th percentiles); and the whiskers extend to 1.5 × IQR. Exact P values are provided as Source data. c, The distribution of IBD density across the 118 chromosomes. The red regions indicate higher IBD density (that is, breeder-favoured haplotypes), and the green regions indicate lower values. Saccharum spontaneum-derived, S. officinarum-derived and recombinant chromosomes are coloured green, red and black, respectively. SUS2 is highlighted in red to facilitate detailed analysis. d, Allele-specific expression shows genes (x axis) with chromosome-specific haplotypes (for example, chromosome 10g5) and progenitor origins (y axis). Haplotypes are indexed arbitrarily for visualization. Expression levels (n = 3 replicates) from mature stem and leaf were normalized as log2[transcripts per million (TPM) + 1]. The black squares highlight breeder-selected haplotypes and the grey areas indicate haplotype absence. e, Haplotypic variations of SUS2, with Ss_hap1 identified as the breeder-favoured haplotype. f, The frequency of SUS2 Ss_hap1 CNVs across 595 samples; the bars represent sample counts and proportion. The broken line represents the average sucrose content, and the error bars indicate the s.e.m. Significance was assessed using one-way ANOVA. g, Differential use of POJ2878 haplotypes exists between Chinese (-C) and non-Chinese (-N) populations.Source dataThe SUS2 gene has four haplotypes: one favourable haplotype from the S. spontaneum subgenome (Ss_hap1) and three from the S. officinarum-derived subgenome (So_hap1–3). Ss_hap1 includes a 27-bp insertion in exon 9 and a 255-bp deletion in exon 11 (Fig. 3e). We identified six unique k-mers to this haplotype and used their average copy number to estimate its prevalence in each cultivar. A strong correlation was found between Ss_hap1 copy number and sucrose content at 270 days after planting, with cultivars carrying 1–3 copies showing substantially higher sucrose levels (Fig. 3f and Supplementary Table 12). However, sucrose content did not increase proportionally with more copies, as excessive S. spontaneum subgenome contributions may be detrimental.Further analysis revealed substantial differences in the use of POJ2878 between Chinese and non-Chinese cultivars. On average, non-Chinese cultivars exhibited a higher IBD density (0.20) compared with Chinese cultivars (0.18; P < 0.001, Mann–Whitney U-test; Fig. 3b), indicating broader adoption of POJ2878 as a genetic donor in non-Chinese breeding programmes. Moreover, IBD analysis revealed distinct genomic regions preferentially selected by Chinese and non-Chinese breeders (Fig. 3g), with the top 5% of IBD windows containing 5,057 protein-coding genes in Chinese and 2,838 in non-Chinese cultivars. Functional enrichment analysis revealed divergent selection pressures: genes in Chinese cultivars were significantly enriched for herbicide response traits, whereas those in non-Chinese cultivars were enriched for abiotic stress response (Fisher’s exact test, P < 0.05; Supplementary Fig. 17). These findings highlight the critical role of POJ2878 in shaping the genetic architecture of modern sugarcane cultivars and underscore region-specific selection pressures in global breeding programmes.Sugarcane domestication and improvementTo investigate the development of key traits in sugarcane, we analysed selective sweeps during three critical phases: natural selection in S. spontaneum, early domestication in S. officinarum and crop improvement in hybrid cultivars through nobilization. Natural selection in S. spontaneum was examined using within-population comparisons with the S. spontaneum 82-114 T2T monoploid assembly as a reference. Early domestication in S. officinarum involved comparisons with its direct ancestor, Saccharum robustum, using the S. officinarum XZ T2T monoploid assembly as a reference. Moreover, the detection of selective sweeps during the crop improvement stage was based on the POJ2878 haplotype-resolved genome assembly.In S. spontaneum, we identified 17.56 Mb selective sweeps, or 2.29% of its 766.92 Mb genome, encompassing 1,600 protein-coding genes (Fig. 4a). These genes were enriched in biological processes related to defence response, probably contributing to the species’ robust resistance (Supplementary Fig. 18). Notable genes included a homologue of Arabidopsis thaliana GLP (AtGLP), essential for root growth and development, and stress-response genes such as homologues of AtRPM1 (pathogen resistance)23 and AtCBL1 (regulator of drought, salt and cold stress responses24). Overexpression of Saccharum hybrid CBL1 (ShCBL1) in sugarcane increased proline content, superoxide dismutase (SOD) activity and malondialdehyde levels (P < 0.05, one-way analysis of variance (ANOVA)), and its overexpression in rice affected COLD1 and ICE1 (Extended Data Fig. 5), enhancing chilling tolerance25,26. These findings align with the long-standing view that S. spontaneum contributed strong ratooning ability and resistance traits to modern sugarcane cultivars.Fig. 4: Analysis of selective sweeps in S. spontaneum, S. officinarum and S. hybrid.The alternative text for this image may have been generated using AI.Full size imagea, Genome-wide distribution of selective sweep signals identified through within-population comparisons in the S. spontaneum population (n = 290 independent varieties). The T2T monoploid genome of S. spontaneum 82-114 was used as the reference genome. b, Selective sweep signals identified through cross-population comparisons in the S. officinarum population (n = 78 independent varieties) against the S. robustum population (n = 43 independent varieties). The T2T monoploid genome of S. officinarum XZ was used as the reference genome. c,d, Selective sweep signals identified through cross-population comparisons with S. spontaneum (c; n = 290) and S. officinarum (d; n = 78) in the S. hybrid population (n = 613). Sweep candidates were defined as genomic windows in the top 5% of genome-wide uStat (a) or XP-CLR (b–d) values. Genes with putative functional relevance are highlighted in the Manhattan plots. e–h, Local population fixation statistics (FST) and XP-CLR profiles at selected target loci (SUS2 (e), FT (f), TB1 (g) and BX8 (h)), highlighting regions under strong selection in the S. hybrid population. i, Expression analysis of allelic genes within selective swept regions related to growth development, vacuole development and disease resistance under selective sweeps. Stem and leaf tissues were collected with three biological replicates per tissue (n = 3). Expression levels are shown as log2[TPM + 1]. j, A proposed model delineating natural and artificial selection in sugarcane. In wild sugarcane (S. spontaneum), genes associated with disease resistance and root development are subject to natural selection. During the early domestication of S. officinarum, selective sweeps targeted genes linked to flowering time and sugar metabolism. After nobilization breeding, crop improvement efforts in modern sugarcane hybrids (S. hybrid cultivars) have driven selective sweeps in genes governing floral development, flowering time, biotic and abiotic resistance, vacuole development and tiller architecture.Source dataThe domestication of S. officinarum, originating in New Guinea from S. robustum5,27, involved substantial genetic changes. Comparative selective sweep analyses between S. officinarum and S. robustum identified 20.22 Mb of domesticated regions, representing 2.30% of the 879.72 Mb genome and encompassing 1,099 protein-coding genes (Fig. 4b). These genes were enriched in biological processes critical to key agronomic traits, particularly carbohydrate metabolic and biosynthetic processes (Fisher’s exact test, P < 0.05; Supplementary Fig. 19). Notably, selected genes included regulators of flowering time (such as RFT128 and TFL429), probably contributing to flowering suppression—a trait that enhances biomass and sugar accumulation. This aligns with findings that homologues of flowering locus T in sugarcane can delay flowering time and modify productive structure30. Key genes involved in sugar metabolism and transport, such as ShFPB (fructose-l-6-biophosphatase)31 and ShINV (responsible for breaking down sucrose into glucose and fructose)32, were also under selection, supporting the early domestication of sugarcane.Selective sweep analyses during the crop improvement process of hybrid cultivars, compared with their progenitor species, identified 4,032 genes (Fig. 4c,d) associated with response to light, carbohydrate metabolic process, response to stimulus and shoot system development (Supplementary Fig. 20). Sugar accumulation and resistance related genes were identified, including homologues of SUS2 (Fig. 4e), SWEET14, TPS1133, BX834 (Fig. 4h) and GSK135. Key genes also include homologues of TB1 (Fig. 4g), which reduces branching for upright plant structure36, FT (flowering locus T; Fig. 4f) and NRT1.1, which facilitates lateral root branching by controlling the transport of the hormone auxin in response to nitrate availability37. Notably, genes under strong artificial selection for vacuole development and cell wall loosening include homologues of TIP138 and QRT139. TIP1 encodes an aquaporin protein that facilitates water transport across the vacuole membrane in Arabidopsis38. Overexpression of ShTIP1 modified leaf width in sugarcane and rice by reducing vein distance without affecting veins and epidermal cell count (Extended Data Fig. 6), suggesting that it has a role in regulating cell size during development. The QRT1 gene encodes a pectin methylesterase in Arabidopsis that is involved in cell wall loosening and modification39.To confirm that the selection signals (Fig. 4e–h) exceed the expectations of random drift, we compared the cross-population composite likelihood ratio (XP-CLR) and FST values of candidate genes against genome-wide empirical distributions derived from all gene regions. Candidate genes (SUS2, FT, TB1 and BX8) were identified as significant outliers (P < 0.05, Fisher’s combined test), with their values in the extreme tails of the empirical distributions (Supplementary Fig. 21). Expression analysis supported their potential functions during the natural and/or artificial selection (Fig. 4i). Together, these genes underpin sugarcane domestication and crop improvement, contributing to traits such as flowering regulation, stress response and sucrose metabolism and storage—key characteristics that define modern sugarcane as a leading sugar crop (Fig. 4j).GWAS reveals key genes for sugar storageSugarcane’s ability to maintain high sugar content is largely attributed to its efficient sucrose storage in stem parenchyma cells40. Our analysis revealed that parenchyma cells in high-sugar-content S. officinarum (10,525 μm2) are significantly larger than those in S. spontaneum 82-114 (6,526 μm2, Mann–Whitney U-test, P < 0.01; Fig. 5a–f). Similarly, high-sugar-content hybrids had larger cells compared with low-sugar-content hybrids (14,862 μm2 versus 6,506 μm2). To further examine this relationship, we measured parenchyma cell density and size across 265 hybrid cultivars using a robust image recognition approach (Extended Data Fig. 7). Significant correlations were observed between these cell traits and Brix (a measure of sugar content; P < 0.05; Supplementary Fig. 22), supporting the potential breeding value of parenchyma cells.Fig. 5: Genome-wide association analysis of parenchyma cell traits.The alternative text for this image may have been generated using AI.Full size imagea–d, Representative stem cross-sections showing parenchyma cell organization in four groups: the two progenitor species (S. spontaneum (a) and S. officinarum (b)), low-sugar-content S. hybrid cultivars (Cul-L) (c) and high-sugar-content S. hybrid cultivars (Cul-H) (d). One representative image is shown for each group. For each group, the microscopy observations were repeated three times independently with similar results. For a–d, scale bars, 500 μm. e, Brix (%) measurements across the four groups. For each biological sample, Brix was measured 15 times (n = 15 independent biological replicates). Data are mean ± s.d. Statistical significance was assessed using a two-sided Student’s t-test. f, Parenchyma cell size across the four groups quantified from 15 microscopy fields of view per biological sample. n = 15 fields of view per group. Data are mean ± s.d. Statistical significance was assessed using a two-sided Student’s t-test. g–i, Genome-wide association results for parenchyma cell size (μm2) (g), cell density (cells per mm2) (h) and Brix (%) (i) in 265 cultivars (n = 265). The y axis shows −log10[P], where the P values indicate significance of k-mer–trait associations, determined using two-sided Wald tests in a linear mixed model using KMERIA. The horizontal dashed lines indicate the Benjamini–Hochberg false-discovery-rate-corrected significance threshold with P values of 5.10 × 10−7 (g), 5.06 × 10−7 (h) and 3.85 × 10−11 (i), respectively. Exact P values for e and f are provided as Source data. **P < 0.01.Source dataTraditional GWASs face comprehensive limitations in polyploid genomes including inability to detect multiallelic variants, neglecting allele dosage effects and inaccuracies in genotyping due to ambiguous short-read alignments. To overcome these challenges, we used KMERIA15, a k-mer-based GWAS approach specifically designed for polyploid genomes (Methods). KMERIA analysis of parenchyma cell traits and sugar content revealed key genes linked to important biological functions (Fig. 5g–i and Supplementary Table 13). These include a homologue of AtMob1A that is essential for organ growth and tissue patterning41, which may regulate cell proliferation and organ size42. We also identified a MATE (multidrug and toxic compound extrusion) transporter family member that is involved in hormone transport and stress responses, highlighting their potential in parenchyma cell development43. Moreover, we identified a WD40-domain-containing protein homologous to the cucumber LITTLELEAF (LL) gene, which is known to control organ size and lateral branching44. This gene may similarly influence parenchyma cell size and contribute to sugarcane’s architecture and sucrose storage.Notably, the SUT2 (sucrose transporter 2), a gene that is essential for sucrose transport, was identified by KMERIA to have a significant association with parenchyma cell size (Fig. 5g). Overexpression of ShSUT2 in sugarcane cultivars significantly increased parenchyma cell size, with a 7.20% enhancement in the OE1 line and a 28.92% increase in the OE2 line (P < 0.0001, Wilcoxon rank-sum tests; Extended Data Fig. 8).DiscussionThis study establishes a comprehensive genomic framework (Supplementary Note 4 and Extended Data Fig. 9) for understanding the genetic basis of sugarcane domestication and improvement. By generating a fully haplotype-phased assembly of the hybrid cultivar POJ2878, which substantially reduced switch errors and collapsed assembly artefacts present in previous assemblies, we identified key genetic innovations that have driven the transformation of sugarcane from wild Saccharum species into a high-sugar, high-biomass crop. In S. officinarum, genes under domestication involved in regulating sucrose metabolism (NINV, FPB) and floral development (for example, TFL4 and AGL80), consistent with selection for delayed flowering and enhanced sink strength. By contrast, S. spontaneum retained alleles associated with disease resistance and ratooning ability, including homologues of RPM1, SERK145 and TB1, which were later introgressed into hybrids during nobilization. We demonstrate that POJ2878 occupies a central position in the sugarcane improvement trajectory. More than 95% of modern cultivars harbour extensive IBD tracts from POJ2878, and around 98% of the genome shows non-zero introgression across the panel, including haplotypes at SUS2, SWEETs, SPSs and SUTs. At the same time, we observe that increasing dosage of the favourable S. spontaneum-derived SUS2 haplotype improves sucrose content only up to a point; excessive S. spontaneum contribution, typically reflecting low nobilization, is associated with reduced agronomic performance. This pattern highlights a general principle of polyploid breeding: beneficial haplotypes often act within an optimal dosage window, and overall subgenome balance cannot be ignored. A haplotype-resolved reference and dosage-aware approaches such as KMERIA provide a practical framework for explicitly managing this trade-off.Our results also connected cellular anatomy to agronomic performance. Differences in parenchyma cell size and density between high- and low-sugar lines, combined with KMERIA signals at Mob1A, MATE transporters, LL-like WD40 proteins and SUT2, indicate that vacuole development and sink cell architecture represent underexplored targets for improving sugar yield. Overexpression of ShSUT2 increased parenchyma cell size, supporting a causal relationship between sucrose transport capacity and sink cell expansion. Nonetheless, given the complexity of sugarcane’s polyploid genome and possible functional divergence among homoeologues, these inferences should be regarded as testable hypotheses that require systematic validation in sugarcane germplasm and field conditions.This study provides a template for genomics-assisted breeding in sugarcane and other polyploid crops. In practice, breeders can now (1) track and optimize the dosage of favourable haplotypes such as the S. spontaneum-derived SUS2 allele; (2) select or engineer Mob1A, MATE or LL-like haplotypes to fine-tune parenchyma cell proliferation and organ architecture; and (3) exploit POJ2878-derived regions while monitoring genetic diversity to avoid over-narrowing the breeding base.The contrasting selection signatures observed in Chinese versus non-Chinese cultivars, for example, enrichment of genes associated with herbicide response versus abiotic stress tolerance, highlight how regional priorities shape the genomic architecture of crop improvement. These patterns support the need for locally tailored genomic strategies that integrate climatic conditions, management practices and market demands, rather than a one-size-fits-all deployment of elite alleles. At the same time, the widespread global reliance on POJ2878 underscores both the value and the potential vulnerability associated with foundational cultivars in polyploid breeding programmes.More broadly, resolving the genomic architecture of sugarcane bridges a critical gap between polyploid genome structure and agronomic function. By integrating long-read and proximity-ligation sequencing, haplotype-aware assembly, k-mer-based association and allele-specific expression profiling, this study establishes a generalizable framework for dissecting complex traits in polyploid crops. The genes, haplotypes and pathways identified here provide immediate targets for improving sugar yield and resilience in sugarcane. As demands for sustainable sugar and bioenergy production intensifies, such polyploid-aware genomic resources and analytical tools will be indispensable for accelerating the development of climate-resilient, high-efficiency cultivars in sugarcane and other staple crops.MethodsPlant materialsFor genome assembly and annotation, we used plant materials including, S. hybrid POJ2878, S. spontaneum 82-114 and S. officinarum XZ. These were cultivated in the greenhouse at Shenzhen. Tender leaves were collected for subsequent genome sequencing.This study also resequenced 981 sugarcane accessions, including 78 S. officinarum, 290 S. spontaneum accessions and 613 cultivated varieties. Among the cultivated varieties, 246 were non-Chinese germplasms, while 327 were core domestic cultivars or breeding lines in China. The plant materials were grown at three experimental sites representing distinct climates: (1) a tropical monsoon climate at the sugarcane research base in Lingao County, Hainan Province (19° 34′–20° 02′ N, 109° 3′–109° 53′ E, altitude: 34 m); (2) a subtropical monsoon climate in Fusui County, Guangxi Zhuang Autonomous Region (22° 38′ 06″ N, 107° 54′ 15″ E; altitude 94 m); and (3) a subtropical plateau climate in Kaiyuan City, Yunnan Province (23° 30′–23° 58′ N, 103° 04′–103° 43′ E; altitude 1,051 m). Buds were first disinfected and then planted using a single-bud method within a randomized complete block design (1.2 m row spacing; 15 cm plant spacing). To ensure uniform germination, the field was subject to standardized management, including regular irrigation and pest and weed control.DNA and RNA sequencingDNA extractionDNA extraction for single-molecule sequencing involved collecting samples and preparing long genomic DNA. The DNA was then purified using the QIAGEN Genomic Kit. For ONT-UL sequencing, the SDS method was used to extract DNA, omitting the purification step to preserve long DNA molecules. The DNA integrity and purity were evaluated using the NanoDrop system. Moreover, the Qubit 4.0 Fluorometer was used to measure DNA concentration.PacBio sequencingThe library preparation process included gDNA shearing, DNA damage repair, end repair, A-tailing, hairpin adapter ligation, nuclease treatment, size selection and polymerase binding. A total of 15 μg of genomic DNA was used for each sample and sheared using g-TUBEs. We removed single-strand overhangs and performed repair, end-repair and A-tailing on the DNA fragments. Subsequently, we ligated the fragments with hairpin adapters, treated them with nuclease and purified the samples. We used the BluePippin system to select fragments with target sizes and the library size was verified in Agilent 2100. HiFi reads were sequenced on the PacBio Sequel Revio platform.ONT-UL sequencingGenomic DNA (8–10 μg per sample) was selected for fragments larger than 50 kb using the SageHLS HMW library system. The ONT-UL reads were sequenced on the PromethION platform.RNA-seqHigh-quality RNA (RIN > 8), extracted and purified using the Omega Bio-tek and Takara kits, was used to construct libraries (NEBNext Ultra) for NovaSeq paired-end sequencing after Agilent 2100 validation.Isoform sequencingThe full-length RNA libraries were constructed based on the Iso-Seq Express 2.0 kit and the Kinnex kit. The cDNA synthesis was performed, followed by PCR amplification with barcoded Iso-Seq primers. The barcoded full-length cDNA products were pooled and sequenced on the PacBio Revio platform.Pore-C library construction and sequencingThe Pore-C library was constructed using an enhanced Pore-C (ePore-C) protocol developed in our companion study14. The ePore-C protocol largely follows the previously published Pore-C methodology12, with several refinements designed to improve data yield. In brief, approximately 2 g of young plant tissue was finely ground in liquid nitrogen and mixed with a prechilled extraction buffer. Cross-linking was initiated by adding formaldehyde to the homogenate, incubating for 25 min with periodic vacuum release and then stopped with glycine. The mixture was filtered and the filtrate was layered onto a sucrose buffer and centrifuged to isolate nuclei, followed by further purification using gradient centrifugation with sucrose and Percoll. The nuclei were washed with PBS.Cross-links were reversed using proteinase K, SDS, Tween-20 and RNase A at 56 °C for 18 h. The sample was divided for DNA extraction using phenol–chloroform, and the aqueous phase was combined and precipitated with NaCl, sodium acetate and ethanol. The DNA pellet was washed, air-dried and resuspended in water. Fragments larger than 1 kb were selected using DNA Clean Beads. DNA concentration and quality were assessed with Qubit and confirmed by agarose gel electrophoresis.Using a modified Nanopore Ligation Sequencing Kit (2.5 µg input; around 1 µg yield), DNA underwent repair and end-prep at 20 °C and 65 °C and ligation and clean-up at 30 °C before flow cell loading for sugarcane genome analysis.Genome assembliesContig-level assemblyApproximately 30× HiFi reads, combined with ONT-UL reads exceeding 100 kb, were processed using the hifiasm46 (v.0.19.1-r559) program using its default settings. The resulting p_utg file, which contained haplotype-phased contigs, was then used for subsequent haplotype-resolved scaffolding.Chromosomal-scale and haplotype-resolved assembly using C-PhasingThe complex hybrid sugarcane genome assembly was successfully achieved using a haplotype-resolved genome scaffolding program, C-Phasing, which was developed in our companion study14. This program comprises five core modules: Hitig, Methalign, Hyperpartition, Kprune, and Scaffolding. In brief, Hitig uses split-read alignment with ONT Ultra-long reads to identify and correct chimeric and collapsed errors, which are critical for accurate haplotype phasing. Methalign leverages the long reads of Pore-C data to improve alignment accuracy by combining traditional sequence alignment with allele-specific 5mC site information to filter ambiguous mappings and enhance read alignment accuracy. Kprune identifies allelic contigs through pairwise alignments and uses a maximum-matching algorithm to detect and remove interallelic and crossallelic signals, retaining only intrahaplotype interactions for further partitioning. Hyperpartition implements a two-layer partitioning strategy using the Louvain community detection algorithm47. It processes the raw hypergraph from Methalign to group allelic contigs into homologous chromosome groups (HCGs). By reweighting edges between allelic and cross-allelic contigs, it refines the hypergraph for accurate haplotype phasing. Scaffolding integrates functionalities from HapHiC48 and ALLHiC49 to efficiently sort and assemble contig groups using parallel computing. This module addresses the challenge of missing signals in homologous regions, ensuring consistent chromosome orientation across haplotypes. The combined approach substantially enhanced the phasing results, which were then manually corrected using Pore-C interactions in Juicebox50. This process ultimately yielded a high-quality, haplotype-resolved genome assembly for hybrid sugarcane.Assessment of genome assemblyWe compared the quality of the POJ2878 genome assembly with three published hybrid sugarcane cultivars (R570 (ref. 7), ZZ1 (ref. 6), and XTT22 (ref. 8)) based on three key criteria: continuity, completeness and accuracy.ContinuityWe measured genome continuity by calculating the contig N50 and the number of gaps for each assembly. This enabled us to compare the structural continuity of the four sugarcane genome assemblies.CompletenessTo evaluate genome completeness, we first used the BUSCO51 tool with the embryophyta_odb10 database to assess the presence of conserved single-copy orthologous genes. Moreover, we applied Meryl52 (v.1.4.1) to generate k-mer databases from next-generation sequencing reads by splitting them into 21-mers. Using these k-mer databases, we calculated k-mer completeness using Merqury52 (v.1.3). Using LTR_FINDER_parallel53 (v.1.2) and LTR_HARVEST_parallel (v.1.1; https://github.com/oushujun/LTR_HARVEST_parallel), we identified LTR elements in each genome, which were further processed using LTR_retriever54 (v.2.9.6). This library was used to annotate LTRs across the genome and calculate the proportion of intact LTRs relative to total LTRs. To provide a genome-wide measure of LTR completeness, we used the raw LTR Assembly Index55. Furthermore, we evaluated genome completeness by analysing the alignment rate of next-generation sequencing reads to the assemblies, the scaffold anchoring rate and the ratio of assembled genome size to estimated genome size. These metrics collectively provided a comprehensive view of the completeness of the four sugarcane genome assemblies.AccuracyThe base-level accuracy was calculated by Merqury (v1.3). We then assessed structural accuracy using three metrics: Switch error, Collapse error and Hi-C H-trans error.Switch errors: we extracted the 1,000 longest ultra-long ONT reads and divided them into 5-kb windows. Each window was searched back to the genome using blastn56 (v.2.9.0), and windows with a primary alignment score at least 1.5× higher than the secondary alignment (and exceeding a score of 1,000) were considered to be valid. Reads with at least five valid windows were retained for analysis. If at least 50% of the valid windows aligned to a single chromosome, the read was assigned to that chromosome. Any valid window that failed to align to the same chromosome was classified as a switch error. The switch error rate was defined as the proportion of switch error windows relative to all valid windows.Collapsed regions: to identify collapsed regions, we divided the genome into 50-kb non-overlapping windows. Mosdepth57 (v.0.3.9) was used to calculate the depth of each window, denoted as xi. The set of all xi values is represented as X, and the frequency of each xi is denoted as P(xi). The mode of X was then determined based on the following formula:$$\mathrm{Mode}(X)=\{{x}_{i}|P({x}_{i})=\max ({P}({x}_{j})),{\forall x}_{j}{\boldsymbol{\in }}X\}$$If xi exceeds 1.5× mode(X), the depth of that window is considered abnormally high due to collapse. The extent of genomic collapse was quantified by dividing the total size of windows exhibiting abnormal depths by the size of the entire genome. This ratio is defined as the collapse error.Hi-C H-trans error: Hi-C alignments by BWA58 with a mapping quality score (MAPQ) of 0 were discarded to ensure reliable mapping. We then used C-Phasing to convert the BAM files into contact maps, capturing interaction frequencies between genomic regions. For each pair of homologous chromosomes i and j, we defined intrachromosomal interaction counts as Cii and Cjj, and interchromosomal interaction counts as Cij. The Hi-C H-trans error for the chromosome pair was calculated using the formula:$${E}_{{ij}}=\frac{{C}_{{ij}}}{({C}_{{ii}}+{C}_{{ij}}+{C}_{{jj}})}$$This error rate reflects the proportion of interactions that erroneously link different haplotypes or non-homologous chromosomes, indicating potential misassemblies or chimeric joins. We averaged the H-trans error across all homologous chromosome pairs to obtain a genome-wide estimate.Identification of telomeric and centromeric sequencesTo identify telomeric and centromeric sequences in the POJ2878 genome, we used quarTeT59 (v.1.2.2), using its TeloExplorer and CentroMiner modules for targeted analysis.Telomeric sequence identificationUsing the TeloExplorer module, we first identified the most enriched telomeric-like repeat sequences at the ends of each chromosome. The distribution of these repeats was then analysed to determine the precise location and copy number of telomeric regions on each chromosome.Centromeric sequence identificationFor centromeres, we applied the CentroMiner module to detect tandem repeat monomers. Candidate centromeric sequences were selected on the basis of their repeat period and copy number. To reduce redundancy, the candidate monomers were clustered, and representative monomers were aligned back to the chromosomes. Regions with continuous matches were designated as candidate centromeric regions. These regions were further refined by considering match length and the abundance of retrotransposons, which are characteristic of centromeric regions. Finally, centromere types were classified based on the ratio of the distance between the centromere and the chromosome end (D) to the total chromosome length (L). Chromosomes were categorized as: (1) telocentric if D/L < 0.001; (2) acrocentric if 0.001 ≤ D/L < 0.1; (3) submetacentric if 0.1 ≤ D/L < 0.4; and (4) metacentric if 0.4 ≤ D/L ≤ 0.5.Analysis of genome architectureSubgenome identificationTo dissect the distribution of ancestral genetic components in the genome, this study selected ten individuals from each representative ancestral lineage to generate high-quality resequencing data (with sequencing depth of over 10×). Using the POJ2878 genome as a reference, we used the commercial GTX (v.2.1.0; http://www.gtxlab.com/en/product/cat) software package for SNP detection and implemented stringent quality control measures. Only SNPs meeting the criteria of alignment quality > 30, base quality > 30 and sequencing depth > 5 were retained, while complex variant types were excluded, leaving only biallelic sites. This high-confidence dataset was used for subsequent analyses.We identified lineage-specific SNPs by defining S. officinarum-specific sites as those where >70% of S. officinarum and S. spontaneum samples were homozygous for the reference (0/0) and alternate (1/1) alleles, respectively. The reciprocal pattern was used to define S. spontaneum-specific SNPs.We performed a sliding-window analysis with a 50 kb window size and 10 kb step size to examine the distribution of these ancestral components across the genome. We counted the number of S. officinarum-specific and S. spontaneum-specific sites in each window. A window was classified as belonging to the S. officinarum lineage if it contained at least 1.5× more S. officinarum-specific sites than S. spontaneum-specific sites, and vice versa for the S. spontaneum lineage. Regions that did not meet these criteria were labelled as undetermined (UN).For regions marked as UN, we applied two methods for further classification. The first method used an optimization strategy based on neighbouring information, reflecting the tendency of chromosomal recombination to occur in large, linked segments. If an UN region was flanked by at least three consecutive windows of the same lineage, it was reclassified according to its neighbours. The second method inferred the dominant ancestral affiliation of the entire chromosome. For each chromosome, windows that were not labelled UN and contained at least five S. officinarum- or S. spontaneum-specific SNPs were considered to be valid. If more than 50% of these valid windows belonged to the S. officinarum lineage, the chromosome’s dominant ancestry was classified as S. officinarum, and any UN regions on that chromosome were redefined accordingly; the same process applied for the S. spontaneum lineage.Identification of recombined chromosomesThe identification of recombined chromosomes was also based on a sliding window approach with the window size set up to one-tenth of the chromosome length and a step size of 1 Mb. If a chromosome contains two or more windows where regions with lower ancestry proportions exceed 60%, it is classified as a recombined chromosome between two subgenomes.Identification of HEsThe homoeologous exchanges (HEs) were identified using classified genomic windows (that is, S. officinarum- and S. spontaneum-assigned windows) as described above. HEs involving a switch from the S. spontaneum subgenome to the S. officinarum subgenome were detected when two consecutive windows, located within an S. officinarum-derived non-recombined chromosome, showed more than 70% of resequenced S. spontaneum samples supporting their origin from the S. spontaneum species. Similarly, HEs involving a switch from the S. officinarum subgenome to the S. officinarum subgenome were identified following the same criteria in reverse.Design of oligo-FISH probes and chromosome paintingHaplotype-specific oligonucleotides were designed against the POJ2878 reference genome using Chorus2 software60 with parameters ‘-l 40 -homology 93 -d 5 -step 1’. The initial oligonucleotides were subsequently filtered against whole-genome sequencing data to eliminate sequences with high coverage depth, which may represent potential repetitive sequences. The resulting oligonucleotides were designated as POJ2878 haplotype-specific probes. Chromosome painting by oligo-FISH was performed as described previously61. Probes were labelled by PCR amplification with Cy3-dUTP or FITC-dUTP (Roche Diagnostics). The hybridization cocktail was composed of 10 μl deionized formamide, 2 μl 20× SSC, 4 μl 50% dextran sulfate and approximately 100 ng of oligonucleotide probes. After denaturation at 95 °C for 10 min, the mixture was applied to denatured chromosome slides and incubated at 37 °C for 16 h, followed by standard washing procedures61. Chromosomes were counterstained with DAPI (Vector Laboratories) and imaged using an Olympus BX53 fluorescence microscope with a cooled CCD camera, then processed through cellSens Dimension 1.9.Allele-defined gene annotation and expressionGenome annotationAn integrative approach was used for gene prediction, combining evidence from three sources: ab initio prediction, homologous protein alignments and RNA-seq read mapping. This process was implemented using the GETA program, using clean RNA-seq datasets, homologous proteins and the POJ2878 genome as references. The GETA pipeline used sequencing-depth-based coverage thresholds to filter low-quality transcripts and refine intron predictions. These refined structures were then used to guide the iterative training of gene models in AUGUSTUS62 (v.3.3.3), a process that continued until the highest predictive scores were achieved. Homologous proteins from six related plant species (S. spontaneum, Oryza sativa, Sorghum bicolor, Erianthus rufipilus, Zea mays and A. thaliana)—retrieved from Phytozome and GWH database—were further refined using GENEWISE63 (v.2.4.1) for protein identification. The final gene models were selected based on sequence conservation, expression levels and AUGUSTUS support scores.To ensure the reliability of annotations, a stringent filtering process was applied. Genes were aligned against the NR database and the PFAM conserved domain database, and their expression levels were calculated using RNA-seq data. Genes were retained if they met at least one of the following criteria: (1) presence of a homologous protein in the NR database; (2) presence of a conserved domain in the PFAM database; or (3) an FPKM value greater than 3 with sequence coverage exceeding 50%.Annotation and analysis of TEsThe transposable elements (TEs) of each genome were identified using the EDTA64 package using the default parameters. This method provides a whole-genome de novo TE annotation by integrating structural and homology-based approaches, filtering out false positives from raw TE candidates and generating a high-quality, non-redundant TE library for comprehensive genome-wide TE annotations. RepeatMasker (http://www.repeatmasker.org) and RepeatModeler2 (ref. 65) were used as the TE libraries for homology-based annotation. Insertion time for full-length LTR-RTs were determined based on the divergence between flanking LTR sequences. Based on the Kimura two-parameter model66, we applied the rate67 of 6.5 × 10−9 to the formula T = K/2r to convert genetic distance into absolute time.Identification of allelic and homoeologous genesTo identify genes with defined alleles, paralogous genes and haplotype-specific genes in the complex polyploid sugarcane genome, we developed a three-step method, as illustrated in Extended Data Fig. 3:Identification of paralogues within each haplotype genome. We constructed the haplotype genome by selecting one chromosome from each homologous chromosome group in the order of haplotype numbering (that is, from g1 to g13). Paralogues within each haplotype genome were identified using hierarchical clustering combined with tree-cutting methods, based on sequence identity and coverage. To ensure accuracy, we dynamically determined the tree-cutting height to achieve paralogue identities exceeding 90% (category 6). Specifically, sequence alignment was performed using DIAMOND68 (--query-cover 60 --subject-cover 60 --id 80), generating a gene–gene matrix where each element represented the product of coverage and identity between gene pairs. Hierarchical clustering was then applied to this matrix using Ward’s method with Euclidean distance as the dissimilarity metric69. This approach minimized within-cluster variance, ensuring that genes within the same cluster exhibited high similarity while maintaining clear distinctions between clusters. A dendrogram was constructed to represent the relationships among genes, with branch heights reflecting dissimilarity between clusters. Starting from a tree-cutting height of 2, the threshold was gradually reduced by 0.1 until paralogous gene pairs with over 90% identity were identified. This step was performed within each subgenome to minimize interference in subsequent allele identification.Identification of syntenic and non-syntenic allelic/homoeologous genes. Alleles were identified using JCVI70 to compare synteny blocks across haplotype genomes. Each haplotype genome was used as a reference to ensure comprehensive gene representation. Syntenic blocks identified from different haplotype reference genomes were merged, and low-quality syntenic gene pairs were filtered using an identity threshold of 80%. High-quality syntenic gene pairs were classified as syntenic allelic or homoeologous genes (categories 1, 2 and 3). For non-syntenic homologous genes, if the gene exhibited over 90% sequence identity with any classified allelic/homoeologous gene, it was considered as non-syntenic allelic or homoeologous genes (category 4).Clustering of unclassified genes and identification of single genes. Unclassified genes were further analysed using Broccoli71, a tool for identifying orthologous protein groups and pairs through phylogenetic and network-based methods. Broccoli performs rapid phylogenetic analysis, builds orthologous relationship networks and applies machine learning to classify groups. Using Broccoli, those unclassified genes were categorized as either non-syntenic allelic/homoeologous gene pairs (category 5) or haplotype-specific genes (category 7).This three-step approach enabled the classification of genes into seven categories: categories 1–5 represent genes with defined alleles, category 6 includes paralogous genes and category 7 identifies haplotype-specific genes (Supplementary Table 9).Allele-specific expression analysis using MAS-ISO-seqTo investigate allele-specific expression patterns in sugarcane, we developed a robust pipeline integrating MAS-ISO-seq data using the program Allele-Express (Supplementary Note 3). This approach enabled precise quantification of gene expression from individual alleles within the complex sugarcane genome.Initially, raw MAS-ISO-seq data were processed to generate HiFi reads using the ccs (https://github.com/PacificBiosciences/ccs) tool. Stringent quality-control measures were applied, filtering reads based on minimum pass number, length, signal-to-noise ratio and quality score. These high-quality HiFi reads were then segmented using skera (https://github.com/PacificBiosciences/skera) split, guided by a custom primer design file, to separate reads originating from different targeted regions. Primer sequences, poly(A) tails and chimeric sequences were subsequently removed using lima (https://github.com/PacificBiosciences/barcoding) and isoseq refine (https://github.com/PacificBiosciences/IsoSeq), yielding full-length non-chimeric reads for downstream analysis.To create a non-redundant reference set, similar transcripts were clustered using mmseqs72, retaining only one copy of identical sequences. The FLNC reads were then aligned to these clustered reference transcripts using minimap273, optimized for splice junctions. The sequencing depth at each site was calculated using bedtools74, and saturation curves were generated to confirm sufficient sequencing depth.A key component of our pipeline, Allele-Express, systematically identified and filtered candidate read alignments for each homologous gene group. Reads sharing the same identifier were grouped and a multi-layered filtering strategy was implemented. Initially, a priority alignment was selected on the basis of mapping quality, edit distance and alignment score. For ambiguous alignments, where a read could potentially map to multiple alleles, we developed two complementary approaches:
Genetic architecture of sugarcane traits in a polyploid genomics framework - Nature
A fully phased genome assembly of the sugarcane foundational cultivar POJ2878 reveals extensive subgenome recombination and non-homologous chromosomal rearrangements.
16,268 words~74 min read