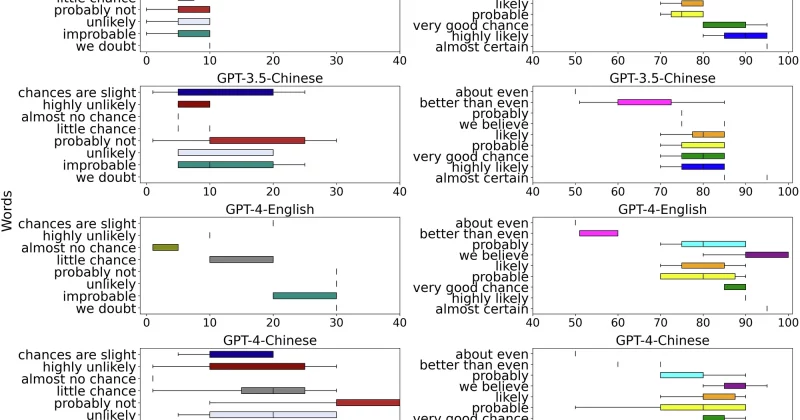
Google Research has published a paper arguing that large language models need to get much better at one deceptively simple task: admitting when they’re not sure about something.
The paper, titled “Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?”, finds that current LLMs are remarkably bad at matching their verbal confidence to their actual internal certainty.
The gap between confidence and competence
Authored by Gal Yona and Roee Aharoni of Google Research, along with Mor Geva from Google Research and Tel Aviv University, the paper was first submitted in May 2024 and revised in September 2024. It was presented at EMNLP 2024, one of the top venues for natural language processing research.
The core contribution is a new metric called “faithful response uncertainty.” It measures the gap between how confident a model actually is in its answer (based on its internal probabilistic outputs) and how confidently it phrases that answer in plain language.