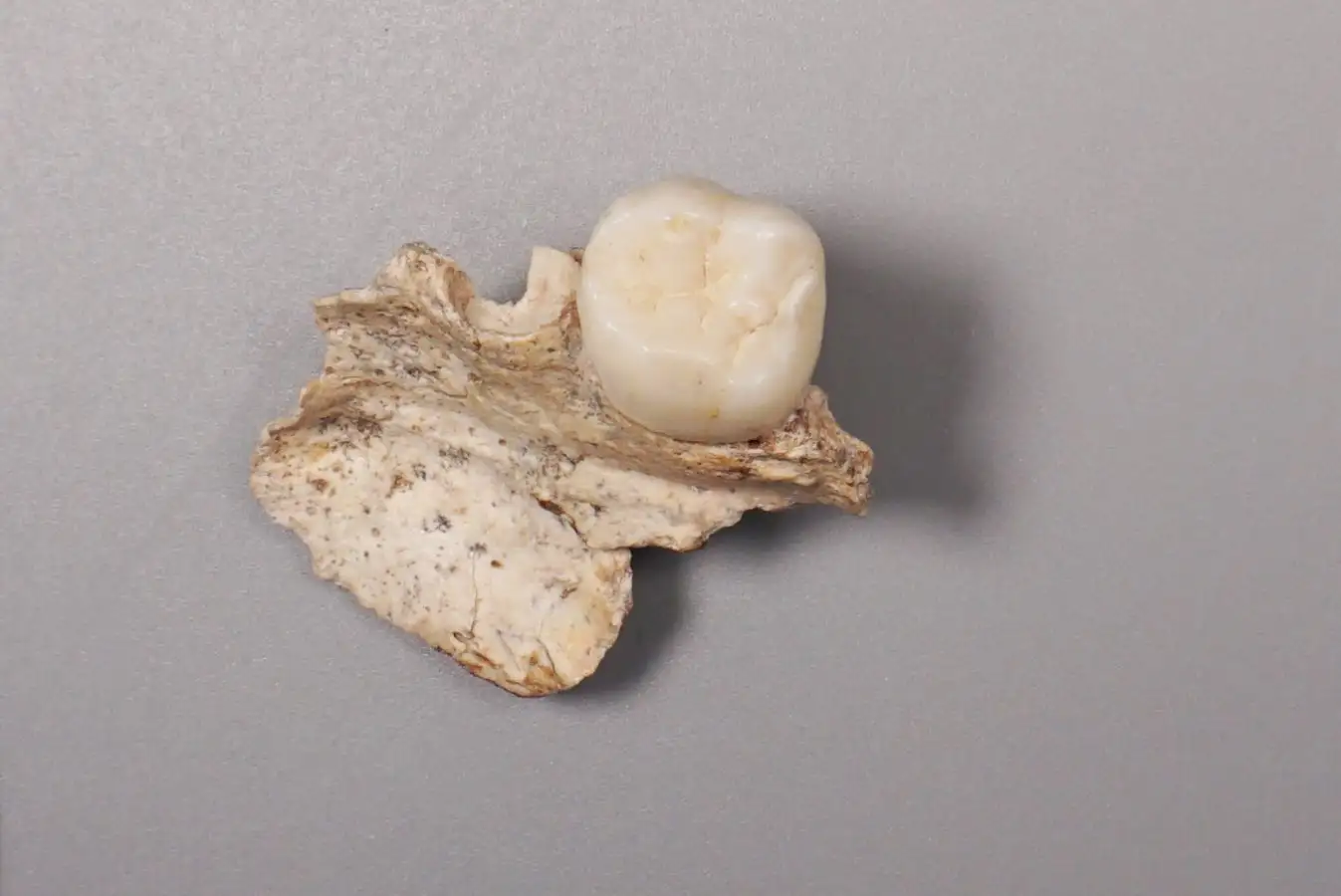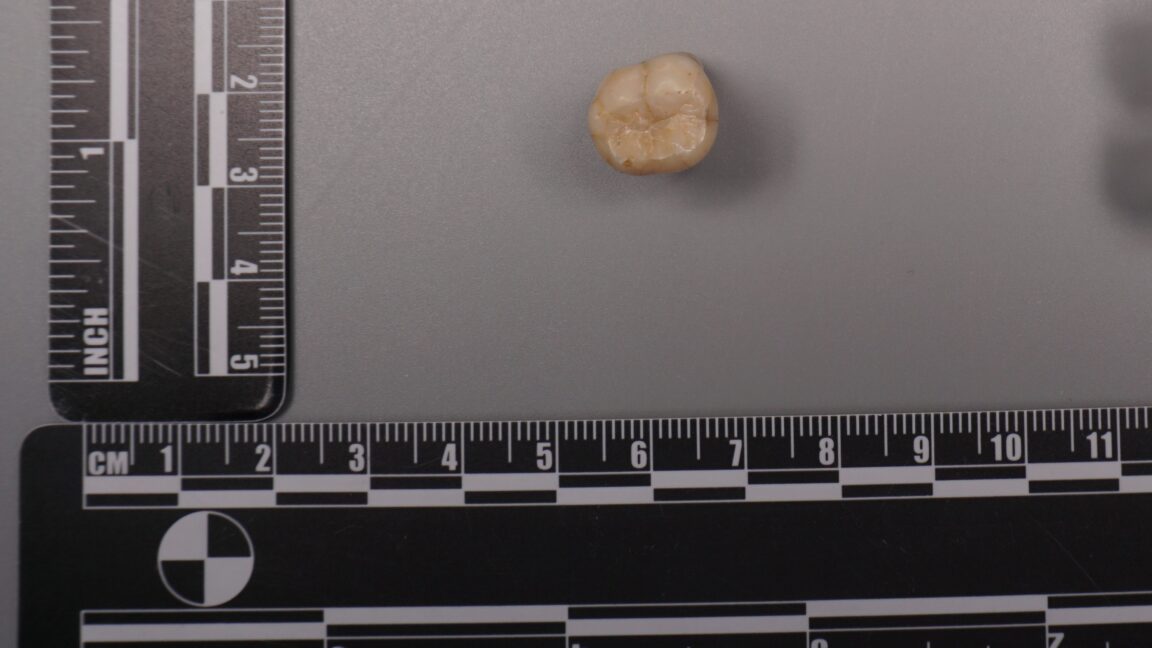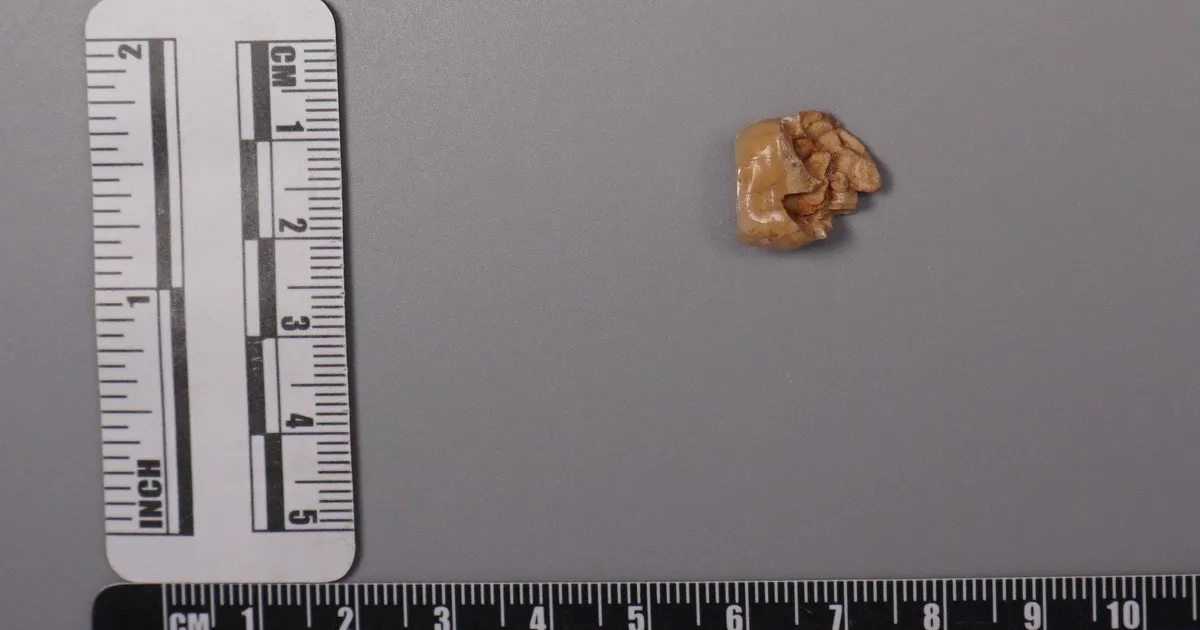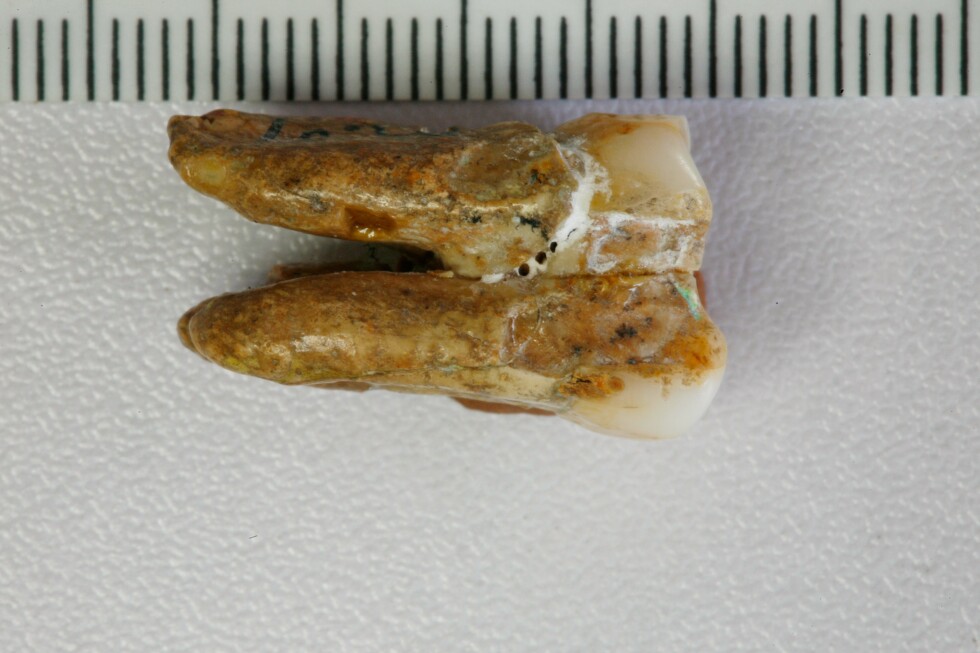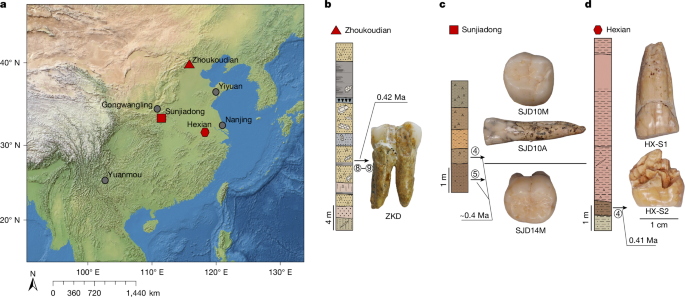
MainBroadly defined H. erectus (H. erectus sensu lato) was widely distributed across three continents and was geologically long-lived1,2,3, lasting nearly 2 million years (Myr). Homo erectus is thought to have spread from East Africa into western Asia (1.8 Myr ago (Ma), Dmanisi, Georgia), marking the earliest generally accepted evidence of the genus Homo outside of Africa4,5. The earliest H. erectus specimen found in Europe is from the TE7 level of the Sima del Elefante site (Sierra de Atapuerca, Spain)6, dated between 1.4 Ma and 1.1 Ma. After dispersing to China and Indonesia, H. erectus persisted in these regions for a considerable geological duration. In China, the record of H. erectus dates back to about 2.1–1.6 Ma (refs. 7,8,9) and disappears roughly 0.4–0.3 Ma (ref. 10). In Java, Indonesia, the fossils of H. erectus range from 1.5 Ma to as recent as 0.1 Ma. Overall, H. erectus has had an important role in human evolution. Understanding the molecular characteristics of this lineage is essential to help us to better understand hominin biology throughout the genus Homo. Nevertheless, the only molecular data previously recovered from H. erectus comprise peptides extracted from a 1.77-Myr-old tooth originating from Dmanisi in Georgia, West Asia. However, these sequences lack any single amino acid polymorphisms (SAPs) that can distinguish H. erectus from other human lineages11.The H. erectus specimen represented by the Zhoukoudian fossils dates from approximately 0.78 to 0.3 Ma during the Middle Pleistocene in northern China12,13. It is frequently used as the primary reference for the overall morphological characteristics of all H. erectus or Asian H. erectus14. This group has had a crucial role in research on the origin and evolution of H. erectus. Studies of the Zhoukoudian fossils have settled debates over whether the Indonesian Java fossils are apes or humans, confirming the systematic position of H. erectus within the human lineage14,15. In addition to the Zhoukoudian fossils, several other Middle Pleistocene H. erectus fossils have been discovered in China, including remains from Hexian, dated to about 0.41 Ma (ref. 16), from Nanjing, dated to at least 0.58 Ma (ref. 17), and from Sunjiadong18, dated around 0.4 Ma (ref. 19). Nanjing and Sunjiadong fossils show similar morphology to the Zhoukoudian fossils, whereas Hexian remains are morphologically closer to Indonesian Java fossils than to Zhoukoudian fossils14,15,18,20. Additionally, some affinities are shared with a Middle–Late Pleistocene mandible from the Penghu Channel in Taiwan, which is purported to be a Denisovan21. Retrieving proteins from more than one of these fossils would help to determine whether they share common molecular characteristics that can distinguish them from others and provide insights into Middle Pleistocene H. erectus genetic material.The fossils used in the protein experiments and analyses of this study are from Zhoukoudian, Hexian and Sunjiadong sites (Fig. 1 and Supplementary Note 1). Although the human fossils excavated at Zhoukoudian22 in Beijing, northern China between 1927 and 1937 were lost, some human fossils were discovered at this site between 1949 and 1951, and again in 1966. The human tooth (PA69)23 used in this study is from layers 8–9 (0.42 Ma (refs. 24,25)), found between 1949 and 1951. We also studied two human teeth from the Hexian site26 in Anhui Province, southern China (0.41 Ma (ref. 16)) and three teeth from Sunjiadong (around 0.4 Ma (ref. 19)) in Henan Province, northern China18. Two of the teeth (12SJD1#10-42 and 12SJD1#10-45) at Sunjiadong are from layer 4, and the other tooth (12SJD1#14-22) is from layer 5 (ref. 18). Altogether, the dating of all 6 samples from these 3 sites yielded an approximate age of 0.4 Myr, making them roughly contemporary and representing individuals from both northern and southern China. Additionally, we included a tooth from an earlier-reported Denisovan skull (minimum age 0.15 Myr) from Harbin, China27,28. Fig. 1: The geographic locations and samples of the Middle Pleistocene H. erectus sites used in this study.The alternative text for this image may have been generated using AI.Full size imagea, The geographic locations of Pleistocene H. erectus sites in China, with sites in the present study highlighted in red. Background raster: Natural Earth, Natural Earth II with Shaded Relief and Water (1:50 m), v3.2.0; public domain (https://www.naturalearthdata.com/downloads/10m-natural-earth-2/10m-natural-earth-ii-with-shaded-relief-and-water/). b, Stratigraphy of the Zhoukoudian site22. The Zhoukoudian tooth, ZKD (PA69) is from layers 8–9. c, Stratigraphy of the Sunjiadong site18. The Sunjiadong 12SJD1#10-42 (SJD10M) and Sunjiadong 12SJD1#10-45 (SJD10A) teeth are from layer 4, and Sunjiadong 112SJD1#14-22 (SJD14M) is from layer 5. d, Stratigraphy of the Hexian site26. Hexian sample 1 (HX-S1) and Hexian sample 2 (HX-S2) are from layer 4 (ref. 16).Preservation of animal fossil proteinsBy first examining protein preservation in animal fossils from Zhoukoudian, Hexian and Sunjiadong, we gained initial insights into the feasibility of the analysis without damaging the ancient human fossils. Tests using matrix-assisted laser desorption/ionization-time-of-flight (MALDI-TOF) mass spectrometry revealed no evidence of ancient proteins in animal dentin or bones from 8 samples at Zhoukoudian, 40 samples from Hexian, and 37 samples from Sunjiadong (Supplementary Data 1). However, enamel from 3, 14 and 5 animal teeth from these respective sites did show protein signals (Supplementary Data 1). The successful retrieval of proteomic data from animal enamel suggests that extracting enamel proteins from human teeth would be feasible.The endogenous enamel proteomeAncient enamel proteins were successfully extracted using minimally invasive sampling techniques from six H. erectus teeth from Zhoukdoudian, Hexian and Sunjiadong sites, and a tooth from Harbin, China (Methods). The database used to search for endogenous peptide sequences included enamel proteins from translated genomes and published proteomes of present-day humans and other hominids11,29,30,31 with spectrum data from liquid chromatography–tandem mass spectrometry (LC–MS/MS) analysed using MaxQuant32, PEAKS Online33, and pFind34 (Methods, Supplementary Note 2). These approaches generated between 4,097 and 22,107 peptide–spectrum matches (PSMs), and between 652 and 3,476 peptides (Extended Data Table 1 and Supplementary Tables 1 and 2) across 7 specimens. Peptides matching multiple genes were considered non-unique and excluded from further analysis.We then evaluated the endogeneity of these enamel proteomes based on several criteria (Supplementary Note 3): (1) the protein and amino acid composition profiles across all seven human samples were similar and consistent with other published ancient enamel proteins35, with minimal exogenous contamination (Fig. 2a, Extended Data Table 2 and Supplementary Tables 3 and 4); (2) peptide lengths and levels of peptide bond hydrolysis were typical of other ancient enamel proteins11,35 (Extended Data Table 1, Supplementary Figs. 1–3 and Supplementary Table 5); and (3) elevated deamidation levels (Fig. 2b and Supplementary Tables 6 and 7) suggest more extensive protein degradation and help to authenticate the ancient proteome11,36. These criteria resulted in 650–3,457 peptides recovered from 6–11 enamel-related proteins (for example, AMEL, AHSG, ALB, AMBN, AMTN, COL17A1, ENAM, KLK4, MMP20, ODAM and SERPINC1) for the 7 samples (Extended Data Table 1 and Supplementary Table 1). The PSM coverage of proteins is shown in Fig. 3a and Supplementary Fig. 4. In total, the consensus sequences of endogenous proteins from each sample were constructed by retaining the overlapping amino acid coverage in PEAKS Online, pFind and MaxQuant (Methods and Supplementary Note 4), which covered 269 to 903 amino acid positions across the 6 H. erectus samples and the Harbin individual.Fig. 2: Ancient enamel protein preservation and sex identification of six Middle Pleistocene H. erectus specimens and the Harbin individual.The alternative text for this image may have been generated using AI.Full size imagea, Number of endogenous peptides after filtering. b, Overall deamidation rates of N and Q residues in the seven new samples and published samples (Penghu 1 and Atapuerca_ATD6–92). MH represents the enamel results of modern humans43. c, The observed ratio (RY) of peptides covering the AMELY-specific position relative to all peptides from both AMELY and AMELX in seven samples of this study (red circles), 4 Paranthropus specimens and 4 known archaic humans (light blue circles), and 16 ancient and 4 present-day modern humans of known sex (orange circles)38,39 labelled as F_ (female) or M_ (male).Fig. 3: PSM coverage and supporting peptides for SAP AMBN(A253G) and AMBN(M273V) in the six H. erectus samples and the Harbin individual.The alternative text for this image may have been generated using AI.Full size imagea, PSM coverage of AMBN. b, The alignments of multiple high coverage human sequences, and the small subset of supporting peptides and fragment ions for the SAPs at AMBN 253 and AMBN 273 in the new samples. e, N-terminal pyroglutamic acid (pyro-Glu) from E; m, oxidated M in ZKD and SJD10M, SJD10A, SJD14M, or dioxidated M in HX-S1 and HX-S2; n, deamidated N; q, deamidated Q (not N-terminal Q) or pyro-Glu from Q (N-terminal Q); y, dichlorinated Y in HX-S1, or chlorinated Y in HX-S2. Peptides marked with an asterisk were from pFind, and the others were from PEAKS. The alignment presents a small subset of the supporting peptides.Sex determinationThe male-specific marker amelogenin Y isoform (AMELY) is a gene located on the Y chromosome that is involved in tooth enamel development, and its presence is used to determine male sex37. However, owing to the restricted database for enamel and the high sensitivity of the searching software, spurious detection of AMELY-specific peptides may result in the false-positive assignment of samples as male38,39. This outcome is not unexpected, as previous research has demonstrated cross-species proteomic effects resulting from search database bias40,41. To address this issue, we used rigorous filtering criteria to ensure the reliability of all identified SAPs in the endogenous proteome (details below), including those used to determine sex in amelogenin.To further validate the sex determination, we established protSexInferer42, a method based on the ratio of peptide counts covering the AMELY-specific positions relative to all peptides from both AMELY and AMELX (RY). Using 16 ancient and 4 present-day modern humans38,39, along with 4 Paranthropus specimens (SK14132, SK830, SK835 and SK850)2 and 4 archaic hominins (Penghu 1 (ref. 35), Dmanisi (D4163) and Atapuerca (ATD6-92)11 and Laos_TNH243) with confirmed sex, samples can be classified as male if RY exceeds 0.058, and female if RY is below 0.024 (Fig. 2c). Using this approach, the Zhoukoudian sample, the two Sunjiadong, two Hexian samples and the Harbin sample with RY from 0.187–0.295 were identified as males (Fig. 2c). The remaining Sunjiadong SJD10A (12SJD1#10-45, an adult), with RY of 0.019, was classified as female (Fig. 2c). The sex determination results were confirmed by the intensity method described in ref. 31 (Extended Data Fig. 1).SAPsTo explore the relationships between these specimens and other humans and primates, we identified peptide counts with amino acid substitutions that are specific to modern humans, Neanderthals, Denisovans, chimpanzees, gorillas and orangutans across all nine endogenous proteins. These required at least two peptides per amino acid allele, derived from different mass spectrometry instruments or laboratories. For all SAPs recovered from the endogenous proteomes, the tandem mass (MS/MS) spectra linked to the relevant PSMs were manually inspected to confirm the presence of typical fragmentation patterns of high-energy collision dissociation, the fragmentation method used in our mass spectrometry. Furthermore, at least three out of four y/b ions bracketing the SAP site were required to ensure high-quality confirmation. SAPs at the C or N terminus of the peptide were accepted if one related PSM contained a single y or b ion or more, as these could only produce one y ion and one b ion at most. All SAPs were confirmed in this way using PEAKS Online, pFind and MaxQuant (Methods), which resulted in two confidently identified SAPs.A new SAP in the ameloblastin protein (AMBN) (A253>G), was identified in all 6 human samples from Zhoukoudian, Hexian, and Sunjiadong, with PSM counts of 124, 3, 9, 191, 24 and 145, and peptide counts of 21, 2, 4, 39, 9 and 35 supporting each sample, respectively (Table 1 and Supplementary Note 5). The highest-quality peptide for this SAP in each of the six samples has at least three y/b ions (Fig. 3b and Extended Data Figs. 2 and 4). Comparative samples with available data covering this position—including mammals, all primates, Homo antecessor from Atapuerca11, H. erectus from Dmanisi11, Denisovan 3, Penghu 1 (ref. 35), all Neandertals and Human Genome Diversity Project (HGDP) modern humans—nearly all carry AMBN A253, with a few mammals having T (horse), S (pig), V (lesser mole-rats) or missing (bovines) residues. Thus, AMBN(A253G), identified in all six human samples from three distinct sites across northern and southern China, representing vastly different geographic regions, has not been previously detected in any other primate species, suggesting that it is likely to be a specific variant for these Middle Pleistocene H. erectus. This mutation causes these six Middle Pleistocene H. erectus samples from Zhoukoudian, Hexian and Sunjiadong to cluster together in the phylogenetic tree (Supplementary Note 6) (posterior probability 100%; Extended Data Fig. 3). These results also indicate that the Hexian teeth can be attributed to H. erectus, and are not Denisovan as has been previously proposed based on morphology21.Table 1 The details of SAPs within Homo identified in six Middle Pleistocene H. erectus specimens and other individualsFull size tableAnother SAP, AMBN(M273V), is also present in all six Middle Pleistocene H. erectus samples (Table 1, Fig. 3 and Extended Data Fig. 4). The corresponding single-nucleotide polymorphism (SNP allele (rs564905233, A>G)) is found in Denisovans and appears to have contributed to modern humans through Denisovan introgression. It exhibits a frequency of 21% in the Philippines, 1.17% in India, 0.71% in Papua New Guinea, and is absent from most other modern human populations44. Notably, genomic studies reveal that Denisovans received 0.5–8% gene flow from a hominin whose ancestors diverged more than 1 Ma from the common lineage ancestral to Neanderthals, Denisovans and modern humans45, and about 15% of these ‘super-archaic’ DNA regions introgressed from Denisovans into Asian and Oceanian individuals46. This situation is similar to what we observe with AMBN(M273V). Consequently, this variant is not exclusive to Denisovans but appears to have been introduced into them through a population linked to Middle Pleistocene H. erectus from Zhoukoudian, Hexian, and Sunjiadong (Fig. 4).Fig. 4: A possible model of gene flow related to AMBN(M273V) among H. erectus associated with the populations of Zhoukoudian, Hexian and Sunjiadong, Denisovans and modern humans.The alternative text for this image may have been generated using AI.Full size imageNeanderthal introgressions are not displayed.Additionally, the DNA region containing rs564905233, which corresponds to the protein at position 273 of AMBN, shows greater sequence divergence between Africans and Denisova 3 than between Africans and the Altai Neanderthal, as identified through sliding window analysis (Methods, Extended Data Fig. 5). This supports the idea that this region, including rs564905233, may originate from a more diverged super-archaic group. In addition, although the AMBN(M273V) variant is homozygous in the more recent Denisovans, Denisova 3 and Penghu 1, it is heterozygous in both known ‘earlier’ Denisovans, Harbin (less than 0.15 Ma) and Denisova 25 (around 0.2 Ma)47 (Table 1, Fig. 3b and Extended Data Fig. 4), indicating that early Denisovans had a lower allele frequency of the derived allele. Furthermore, the morphology of Zhoukoudian and Hexian is distinct from that of the Harbin cranium48. Therefore, because of differences in age, morphology and known genetic variants, Zhoukoudian, Hexian and Sunjiadong can be excluded from the early Denisovans.Discussion and conclusionsRecent research has demonstrated the potential of ancient protein analysis to uncover human evolutionary history11,35,36,49,50. However, genetic data about H. erectus, a key hominin and the first to travel to and inhabit geographically diverse regions, are scarce. The enamel proteins obtained from six Middle Pleistocene H. erectus fossils from Zhoukoudian, Hexian and Sunjiadong—three well-known sites spanning northern and southern China—permit a rare insight into the genetic makeup of H. erectus.Morphological variability among these three sites, especially the Hexian samples, which differ from those of Zhoukoudian and Sunjiadong, prompted discussion about whether they are more closely related to H. erectus from Indonesia or possibly Denisovans14,15,18,20,21. Protein evidence clearly shows that the two Hexian specimens possess the newly identified AMBN(A253G) mutation, as do the H. erectus specimens from Zhoukoudian and Sunjiadong, and that this mutation is not found in Denisova 3, Penghu 1 or Harbin, placing them within H. erectus. Further palaeoproteomic research is needed to explore the molecular diversity within H. erectus.The AMBN(A253G) and AMBN(M273V) variants are potentially specific to the populations to which these six Middle Pleistocene H. erectus specimens belonged. Notably, AMBN(A253G) has not been observed in any humans or primates before, making this finding highly notable. These H. erectus specimens come from three sites across East Asia, all dating to around 0.4 Ma, and Denisovans diverged from Neanderthals around 0.38–0.47 Ma (ref. 45). The known range of Denisovans includes Siberia, the Tibetan Plateau, Harbin in northeast Asia and the Penghu Channel in Southeast Asia, and these three H. erectus sites are from both northern and southern China. Their shared habitats create opportunities for interactions between populations related to these Middle Pleistocene H. erectus individuals and Denisovans. The identification of the derived AMBN(M273V) variant in all East Asian H. erectus specimens of this study and its occurrence in Denisovans, makes H. erectus a candidate source for the super-archaic introgressed DNA identified in the Denisova 3 genome. This variant is likely to originate from populations related to Late Middle Pleistocene H. erectus that interacted with Denisovans during the periods when these groups coexisted51 in East Asia. Further research on H. erectus, including molecular data across different periods and regions, will help to clarify their microevolution, population diversity and interactions with Denisovans.MethodsProtein extractionAnimal fossilsPowder was drilled from the dentin (Supplementary Data 1), then mixed with 1.5 ml of 0.6 M HCl for decalcification. The precipitate was washed with ultrapure water at least 3 times until the pH reached approximately 7. Then, 200 µl of 50 mM NH4HCO3 was added, and the mixture was incubated at 65 °C for 3 h to extract soluble proteins. The supernatant containing the proteins was then transferred into a new centrifuge tube, and 1 µg of trypsin (Promega) was added. The mixture was incubated at 37 °C for 18 h. A 2.5% trifluoroacetic acid (TFA) solution (final concentration 0.1%) was added to stop the reaction. Subsequently, the trypsinized peptides were desalted and purified using C18 ZipTips57. For enamel samples, the powder was mixed with 1 ml of 5% HCl37 for decalcification, and the acid was replaced daily until the reaction ceased. The acid solution containing dissolved enamel peptides was concentrated using a vacuum concentrator, and the peptides were then desalted and purified using C18 ZipTips58.Peptides were eluted into a solution of 80% acetonitrile with 0.1% TFA for MALDI-TOF mass spectrometry analysis. All sample preparations were performed in the dedicated clean room at the Molecular Paleontology Laboratory, IVPP of the Chinese Academy of Sciences in Beijing.Hominin fossilsAn acid etching method was used to extract protein from tooth enamel, modified from the process described in ref. 37. Disposable toothbrushes were used to remove surface contaminants from a small area of the enamel for etching. At the same time, the remaining teeth were wrapped with parafilm to prevent contact with any liquids. Before etching, the small enamel area was initially washed with 3% H2O2 for 30 s, followed by a rinse with ultrapure water. Approximately 100 µl of 5% (v/v) HCl was placed in the cap of a 1.5-ml microcentrifuge tube. A 2-min etch was performed by immersing the etching region in the HCl solution, and the initial etch solution was discarded. A second etch, lasting 15 min, was carried out in the cap of another separate microcentrifuge tube, and the etch solution was retained. This second etch was repeated, and the etch solutions were combined. After etching, the etched area was treated with 100 µl of 50 mM ammonium bicarbonate solution for 1 min to neutralize the acid. It was then rinsed with ultrapure water for 30 s and dried. The combined etch solution was then desalted using C18 ZipTips (Thermo Fisher Scientific) and eluted into a solution of 0.1% TFA and 80% acetonitrile (ACN). The peptide mixture (50 µl) was further divided into three aliquots; one aliquot was composed of 16 µl, among which 3 μl was used for the MALDI-TOF mass spectrometry test and 13 µl was retained as backup in our laboratory; two aliquots (each composed of 17 µl) were dried for LC–MS/MS analysis in two independent laboratories. All sample preparation for the experiment was conducted in the dedicated clean room at the Molecular Paleontology Laboratory, IVPP of the Chinese Academy of Sciences in Beijing.MALDI-TOF mass spectrometry analysisThe peptide mixture was analysed on a Bruker autoflex maX MALDI-TOF mass spectrometer. In detail, 1 µl of peptide mixture was spotted onto a MTP384 Bruker ground-steel MALDI target plate, and 1 µl of α-cyano-4-hydroxycinnamic acid matrix solution (1% in 50% ACN/0.1% TFA (v/v/v)) was added on top. They were mixed, dried, and analysed on the mass spectrometer with a m/z range of 700–3,500. Each sample was analysed in triplicate. The raw data files were processed by mMass (v5.5.0)59.LC–MS/MS analysisFor each hominin fossil, the eluted peptides from the enamel extraction were analysed under DDA mode in triplicate, including two runs on an Orbitrap Fusion Lumos mass spectrometer (Thermo Fisher Scientific) at Capital Medical University, Beijing, and one run on an Orbitrap Exploris 480 mass spectrometer (Thermo Fisher Scientific) at Fudan University. Both devices were coupled to an Easy nLC 1200 HPLC system (Thermo Fisher Scientific).For the Orbitrap Fusion Lumos at Capital Medical University, the peptides were initially loaded onto a 100 μm internal diameter × 2 cm trap column and then separated on a 150 μm internal diameter × 15 cm analytical column. Both columns were packed in-house using 3 μm reversed-phase silica (Reprosil-Pur C18 AQ, Dr. Maisch). The peptides were eluted using a 120 min linear gradient programme (0–8 min, 7–11% B; 8–96 min, 11–28% B; 96–108 min, 28–40% B; 108–113 min, 40–90% B; 113–120 min, 90% B) at a flow rate of 500 nl min−1. Buffer A was 0.1% formic acid in water, and buffer B was 80% acetonitrile and 0.1% formic acid. The MS1 data were acquired across 375–1,400 m/z, with a resolution of 120k at m/z 200, a 250% AGC target, and a maximum injection time of 50 ms. The MS2 scans were performed with a resolution of 15k at m/z 200, an AGC target of 100%, a 35% normalized collision energy, and a maximum injection time of 22 ms.For the Orbitrap Exploris 480 at Fudan University, Shanghai, the peptides were separated on a 75 μm internal diameter × 25 cm analytical column, which was packed in-house using reversed-phase silica of 1.9 μm (Reprosil-Pur C18 AQ, Dr. Maisch). Buffer A was 0.1% formic acid in water, and buffer B was 80% acetonitrile and 0.1% formic acid. An 80 min gradient was used with the following profile: 5–8% B, 2 min, at a flow rate of 200 nl min−1; 8–44% B, 38 min, 200 nl min−1; 44–70% B, 8 min, 200 nl min−1; 70–100% B, 2 min, 200 nl min−1; 100% B, 10 min, 200 nl min−1; 100–5% B, 2 min, 200 nl min−1; 5% B, 2 min, 300 nl min−1; 5–100% B, 6 min, 300 nl min−1; 100% B, 10 min, 300 nl min−1. Full mass spectrometry scans were acquired for the first 65 min, after which the column was washed and re-equilibrated for 15 min without data acquisition. The full mass spectrometry data acquisition was conducted across the range of m/z 350–1,600, with a resolution of 60k at m/z 200. The AGC target was set to ‘standard’, and the maximum injection time mode was set to ‘auto’. The MS/MS spectra were acquired with a resolution of 15k at m/z 200, a maximum injection time of 30 ms and a normalized collision energy of 30%. The AGC target was also set to standard.For each animal fossil, the eluted peptides from enamel extractions were analysed for one run under DDA mode on the Orbitrap Fusion Lumos mass spectrometer (Thermo Fisher Scientific), either at Capital Medical University or Fudan University. For the Orbitrap Fusion Lumos at Capital Medical University, the liquid chromatography gradient and mass spectrometry parameters were the same as those of the hominin fossils. The Orbitrap Fusion Lumos at Fudan University was also interfaced with an Easy nLC 1200 HPLC system (Thermo Scientific). The peptides were separated on a 75 μm internal diameter × 20 cm analytical column packed with 1.9 μm reversed-phase silica. Mobile phase A consisted of 0.1% formic acid, and mobile phase B consisted of 80% acetonitrile and 0.1% formic acid. An 80 min gradient was used with the following profile: 2–5% B, 3 min, at a flow rate of 200 nl min−1; 5–35% B, 40 min, 200 nl min−1; 35–44% B, 5 min, 200 nl min−1; 44–100% B, 2 min, 200 nl min−1; 100% B, 10 min, 200 nl min−1; 100–5% B, 2 min, 200 nl min−1; 5% B, 2 min, 300 nl min−1; 5–100% B, 6 min, 300 nl min−1; 100% B, 10 min, 300 nl min−1. Full mass spectrometry scans were acquired for the first 65 min, after which the column was washed and re-equilibrated for 15 min without data acquisition. The full mass spectrometry data acquisition was conducted across the m/z range 350–1,600, with a resolution of 60k at m/z 200, a 100% AGC target, and a maximum injection time of 50 ms. The MS/MS spectra were acquired with a resolution of 15k at m/z 200, a 100% AGC target, a 30% normalized collision energy, and a maximum injection time of 30 ms. Blank extractions were processed concurrently to monitor the exogenous contaminants during the procedure.Data search strategyMaxQuant (v2.6.0.0)32, PEAKS Online (v12)33 and pFind (v3.2.1)34 were used to search the raw data. The H. erectus raw files were searched with the corresponding laboratory blanks and modern H. sapiens raw files43 against the ‘Hominidae enamel database’, supplemented with the contaminant database. Unspecific digestion was selected in each software. The animal raw files were searched against the ‘mammal enamel database’.Database compositionThe ‘Hominidae enamel database’ comprised 13 selected enamel proteins from Hominidae. Besides the commonly used 12 proteins (AHSG, ALB, AMBN, AMELX, AMELY, AMTN, COL17A1, ENAM, KLK4, MMP20, ODAM and TUFT1), SERPINC1 was also added because we identified this protein in Harbin with abundant peptides and elevated deamidation rates (nearly 100%), and this protein was also reported in modern enamel60,61. The sequences were retrieved from UniProt, downloaded from the ‘Hominid Palaeoproteomic Reference Dataset’ (https://zenodo.org/records/7728060), translated from the genomes of public projects30, and specific sequences from published palaeoproteomes11. The ‘mammal enamel database’ was composed of mammal sequences of the same enamel proteins above, retrieved from UniProt using the gene names and ‘Mammalia (mammals) [40674]’. The contaminant database was composed of a previously published contaminant database62, the cRAP database (https://www.thegpm.org/crap/), and the contaminant database from MaxQuant (v2.6.0.0). The ‘Hominidae enamel database’ was accessible through the ProteomeXchange Consortium (Data availability).PEAKS searchThe precursor ion (MS1) mass tolerance was set to 10 ppm, with a fragment ion (MS2) mass tolerance of 0.02 Da for all PEAKS searches, with unspecific digestion. Variable modifications included deamidation (NQ), oxidation (M), hydroxylation (P), phosphorylation (STY), N-terminal pyro-Glu from E, and N-terminal pyro-Glu from Q, with no fixed modifications and up to three modifications allowed per peptide. The peptide length was set to 6–45. PSMs were filtered using a false discovery rate (FDR) of 1%, and proteins were filtered with criteria of −10logP ≥ 20 and average local confidence (ALC) ≥ 50% (de novo only).After our initial search with PEAKS, additional variable modifications were included in the second-round search for Hexian H. erectus samples: chlorination and dichlorination of tyrosine residues, dehydration, dioxidation (W), carbonyl E, dioxidation (M), oxidation (HW), ornithine derived from arginine, tryptophan oxidation to kynurenine, tryptophan oxidation to oxolactone, and proline oxidation to pyroglutamic acid. Up to five modifications per peptide were permitted. The peptide length range was set to 6–30.After removing peptides from the contaminant database and those detected in the extraction blank samples or matching multiple genes, the deamidation rates of glutamine (Q) and asparagine (N) were calculated for each sample based on PSM counts. We used auxiliary tools for PSM prediction with PEAKS.pFind searchWe included Deamidation [N], Deamidation [Q], Oxidation [M], Oxidation [P], Oxidation [W], Gln->pyro-Glu[AnyN-termQ], Glu->pyro-Glu[AnyN-termE], Pro->pyro-Glu[P], Phospho[S], Phospho[T], Phospho[Y], Dehydrated[S], Dehydrated[T], Dehydrated[Y], Arg->Orn[R], Dioxidation[M], Dioxidation[W], Thiazolidine[W], Trp->Kynurenin[W], Trp->Oxolactone[W], Ammonia-loss[N], His->Asp[H], Pro->HAVA[P], and Amidated[AnyC-term] as variable modifications, with no fixed modifications included. Spectra FDR was set at 1%, and protein FDR was 10%. The mass range of each peptide was set from 350 to 4,000 Da. Open search was enabled. Within pFind’s modification configuration, the default mass ‘X’ is preset to that of isoleucine/leucine. To avoid incorrect identification of the X residue, we set its mass to 6,228.71 Da (Sm41), which substantially exceeds the mass of any natural amino acid. Therefore, any in silico peptide with an X produces abnormal theoretical precursor and fragment ion masses, effectively preventing its matching to experimental spectra during database searches and thus reducing false positives from these ambiguous sequence regions. The other parameters were the same as the settings in PEAKS.After our first-round search with pFind, some additional variable modifications were selected for inclusion in the second-round search for Hexian H. erectus samples: Chlorination[Y], dichlorination[Y], Carbonyl[E], and Dioxidation[P](Pro->Glu[P]).MaxQuant searchNo fixed modifications were specified. Variable modifications included Deamidation (NQ), Phosphorylation (STY), Gln to N-terminal pyro-Glu, Glu to N-terminal pyro-Glu, Dioxidation (MW), Oxidation (M), Oxidation (P), and Oxidation (W). PSM FDR was set at 1% for all 7 samples. The search also enabled the identification of dependent and secondary peptides. The remaining parameters were set to their default values. After the search, the deamidation rates of N and Q were calculated63 for each sample.In addition, we determined the extra variable modification for Hexian H. erectus samples with PEAKS and pFind results. Cl(Y) and diCl (Y) were added for HX-S1 (both post-translational modifications were self-made in Configuration-Modifications), and Cl (Y) and Dehydrated (STY) were included for HX-S2.Considering the high resolution of the instrumentation used, we also reduced the precursor ion (MS1) mass tolerance to 5 ppm and repeated all analyses in PEAKS and pFind. The results were similar, and the two main SAPs (AMBN 253 and AMBN 273) within the Homo genus were consistently identified (Supplementary Table 8). As the final results do not change significantly, we focus mainly on the results from the commonly used 10 ppm search to make our results more comparable to previous studies.Construction of the consensus protein sequences and phylogenetic analysisConsensus sequences of endogenous proteins were reconstructed for phylogenetic analysis (Supplementary Data 1). Peptides shorter than eight amino acids or with abnormal or artificial post-translational modifications were excluded for the consensus sequence reconstruction of each endogenous protein. Only alleles with a PSM count ≥2, a PSM ratio ≥10%, and an intensity ratio ≥10% were considered reliable and retained. For heterozygous sites, at least two peptides were required per allele. The heterozygous variant site, observed only in the Harbin specimen, was identified with 79 peptides for the V allele and 38 for the M allele at position 273 in AMBN (Table 1). We include both alleles of the Harbin consensus in Supplementary Data 2. We performed additional AMELY sequence correction as described in Supplementary Note 4.The protein data in the phylogenetic tree include Denisova 3 (ref. 52), two Neanderthals (Altai, Vindija33.19)45,53, two modern humans from the HGDP project (San, HGDP0987; Bougainville, HGDP01027)30, a chimpanzee (Pan)29, and a Gorilla29. We used PartitionFinder2 (v2.1.1)64 to identify the best partitioning schemes and amino acid substitution models for our dataset. Then, we built a consensus Bayesian phylogenetic tree using the software MrBayes (v3.2.6)65, running 8 Markov Chain Monte Carlo (MCMC) chains for 1 million iterations in 2 independent runs. Sampling was done every 500 generations, and the first 200,000 iterations were discarded as burn-in. The tree was plotted with FigTree v1.4.4 (http://tree.bio.ed.ac.uk/software/figtree).DNA analysisSliding window analysisVariant sites were identified where either Denisova 3 or two Neanderthals (Vindija33.19 and Altai) differed from two modern African diploid genomes (S_Khomani_San-1.DG, S_Mandenka-2.DG) from the phased Simons Genome Diversity Project panel (SGDP) (https://sharehost.hms.harvard.edu/genetics/reich_lab/sgdp/phased_data2021)66,67. For each of 129 overlapping 20 kb windows (with 2 kb steps), pairwise matching rates were calculated for variants between each African haploid and each archaic artificial haploid of either Denisova 3 or the Altai Neanderthal (where each variant is randomly assigned to a haploid to preserve all variants), covering in total 276 kb of DNA sequence surrounding the rs564905233 SNP. For each window, statistical significance of the differences between the African–Denisovan and African–Neanderthal matching rates were assessed using a Wilcoxon rank-sum test, and a permutation test (n = 1,000 permutations). The Wilcoxon rank-sum test was used to compare distributions of pairwise matching rates, with W representing the sum of ranks in the African–Denisovan group. The permutation test was used to evaluate differences in mean matching rates. No adjustments were made for multiple comparisons, since each window was analysed independently to identify localized regions of divergence. All statistical tests were performed as two-sided tests. Full results, including W, exact P values, and the number of comparisons per window, are provided in Supplementary Data 3.Ethics statementPermission to test for ancient proteins in the human specimens from this study was granted by the collection room of the IVPP, the Hexian Culture, Tourism, and Sports Bureau, and the Luanchuan County Culture, Radio, Television, and Tourism Bureau. The work was conducted in collaboration with local researchers, who are co-authors because of their contributions to assembling archaeological materials and/or discussions that informed the study.Reporting summaryFurther information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Enamel proteins from six Homo erectus specimens across China - Nature
Palaeoproteomic analysis of ancient enamel proteins extracted from Middle Pleistocene Homo erectus specimens from the Zhoukoudian, Hexian and Sunjiadong sites in China suggests that they are a new genetic monogroup, and super-archaic introgression in Denisovans is likely to have originated from H. erectus.
8,055 words~37 min read