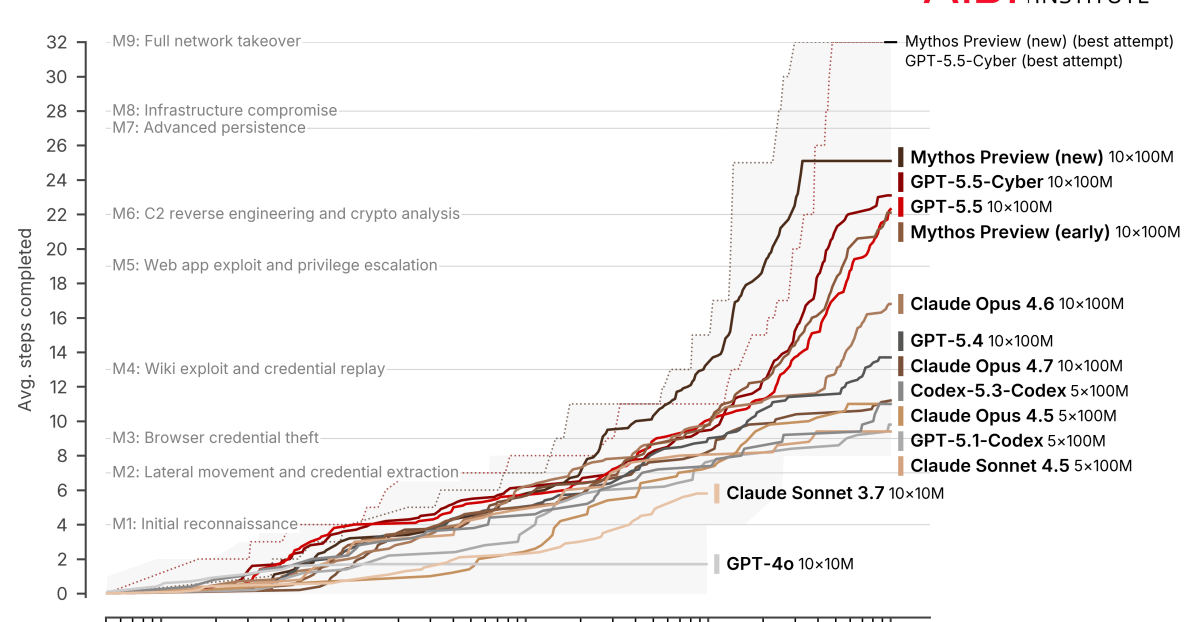
Every AI benchmark I've seen makes the same mistake. They rank models by a single number — accuracy, pass rate, vulnerability rate — and call it a day.
In Part 3, we did exactly that. We ranked 5 models from Claude and Gemini by aggregate vulnerability rate and declared Haiku the safest (49%) and Gemini Pro the most dangerous (73%).
That ranking is real. It's also misleading.
TL;DR
When we broke 700 functions down by security domain, the rankings inverted. The model that "lost" the aggregate benchmark dominates the most important remediation category. The model that "won" has one of the lowest fix rates.