HomeAI · summaries
Storia in 14 fonti
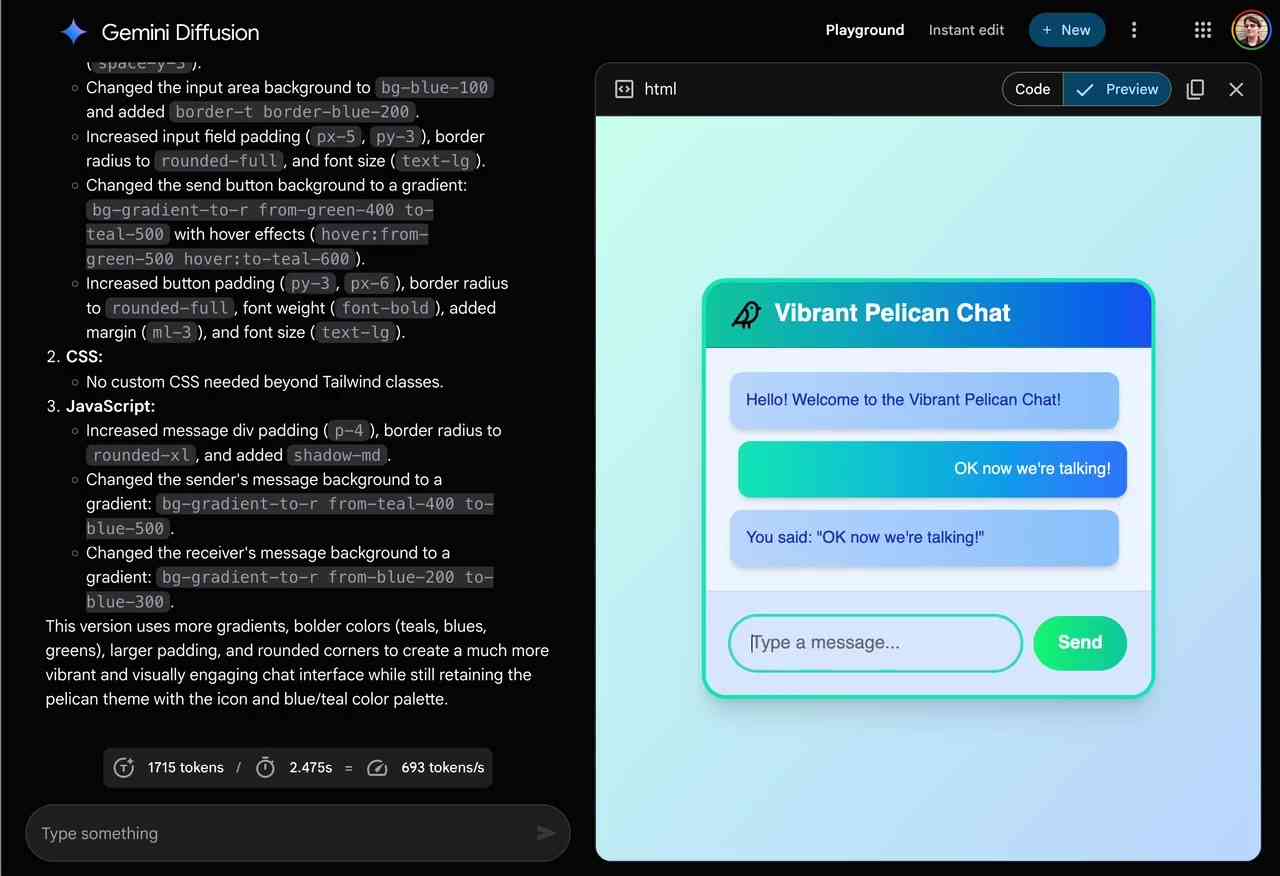
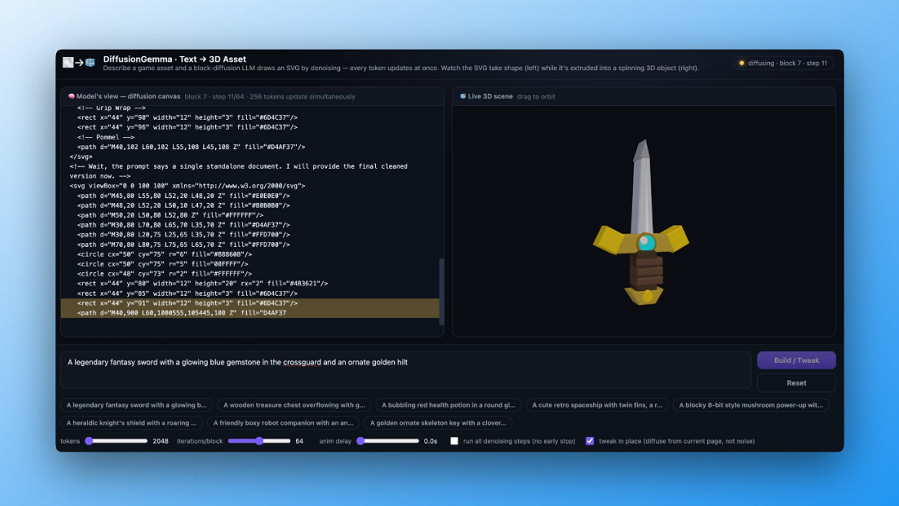
Gemini Diffusion
Another of the announcements from Google I/O yesterday was Gemini Diffusion, Google's first LLM to use diffusion (similar to image models like Imagen and Stable Diffusion) in place of transformers. …
Confronto fonti
6 prospettive sulla stessa storiaTimeline cronologica
- ·
cryptobriefing.com

DiffusionGemma offers 4x faster output with simultaneous text generation
DiffusionGemma generates text up to 4x faster than traditional models by producing entire blocks simultaneously, achieving roughly 1,479 tokens per second.
- ·
developer.nvidia.com

Run DiffusionGemma on NVIDIA for Developer-Ready, High-Throughput Text Generation | NVIDIA Technical Blog
Developers building real-time AI—such as chat assistants, copilots, and agentic workflows—are often constrained by token-by-token generation speed. This limits responsiveness,…