Agent observability gets weirdly polite at the exact moment it should get nosy. It records the model call, stores the prompt, counts tokens, and then loses interest right when the agent starts touching software.
That makes the trace look clean and the incident feel impossible.
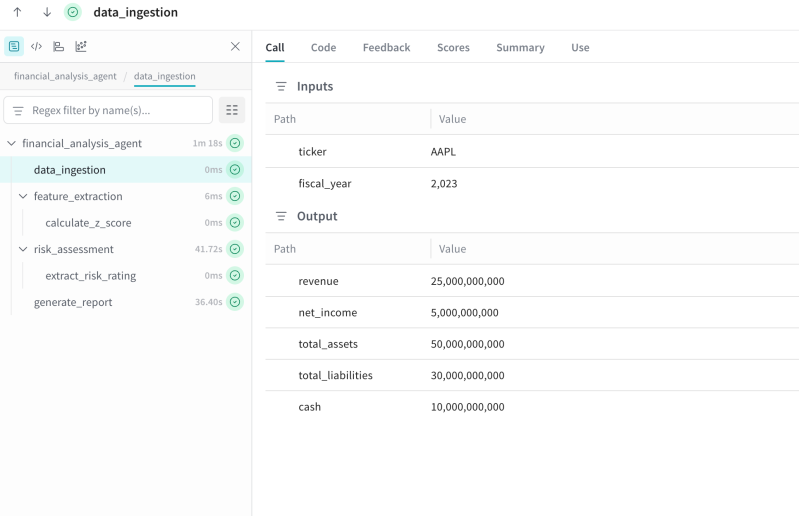
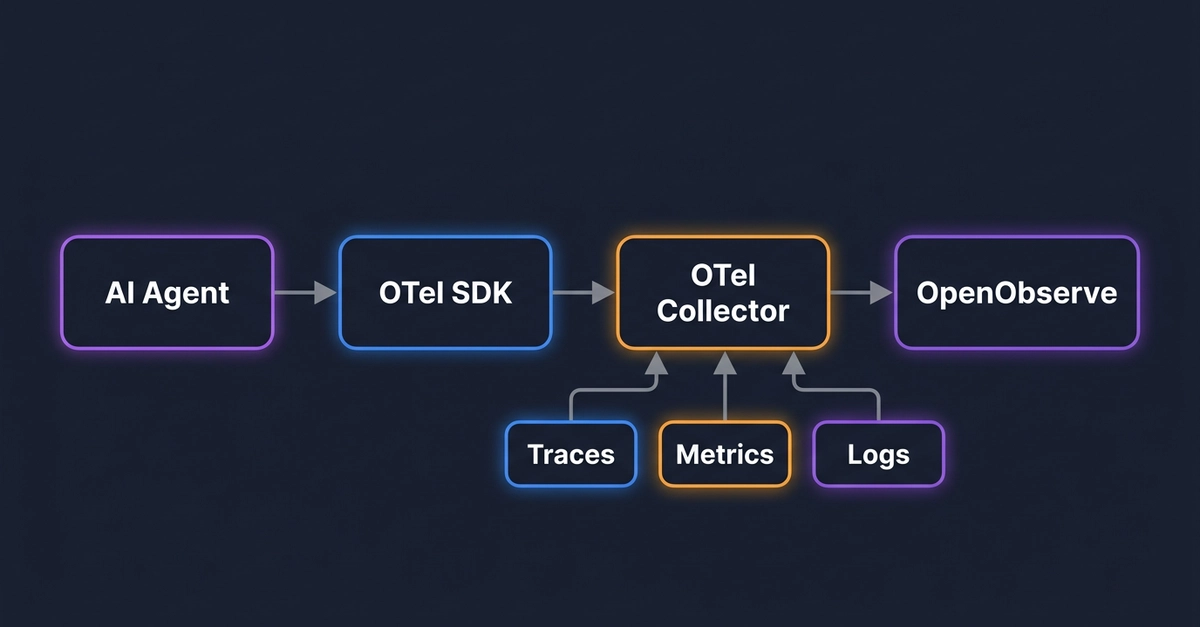
The failure rarely lives inside the LLM span. Honeycomb's Agent Timeline instrumentation guide says a GenAI span can be any work the agent caused: model calls, tool calls, handoffs, downstream services, database queries, and background jobs. That is the right unit of observation. The agent is runtime software making choices and causing side effects.
The conversation ID is where that reality starts to show up.
The trace breaks where the work starts