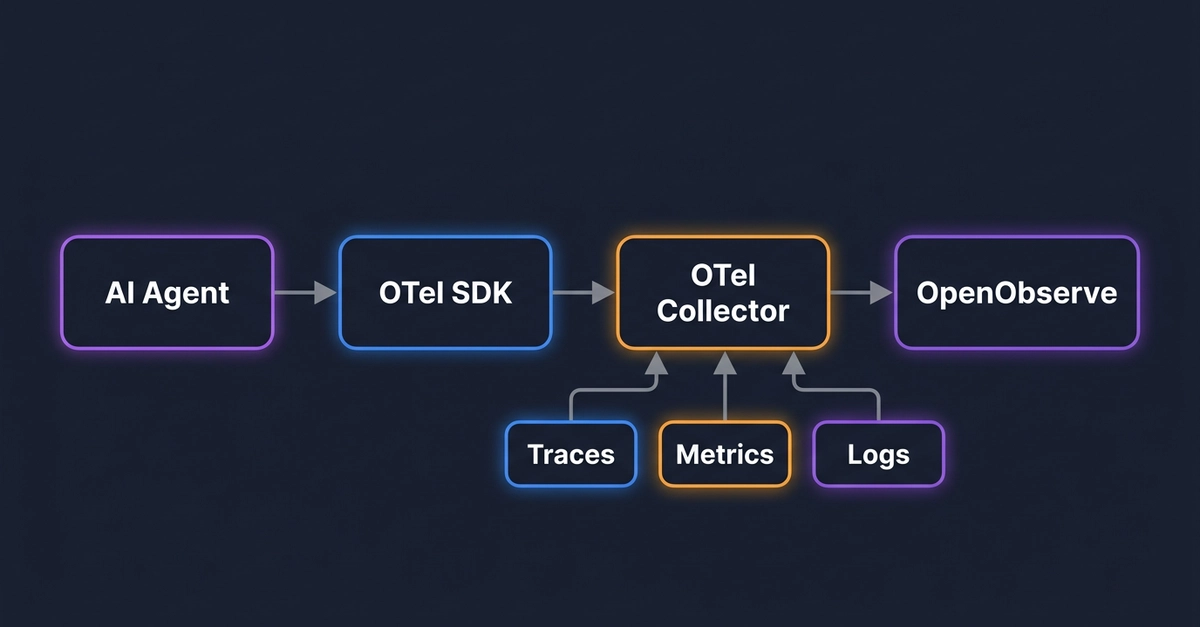
Most discussions about agent observability read like outdated compliance checklists with “AI” substituted for older technologies. They emphasize comprehensive logging, evaluation metrics, and governance frameworks—but provide no actual code examples or guidance for real debugging scenarios.
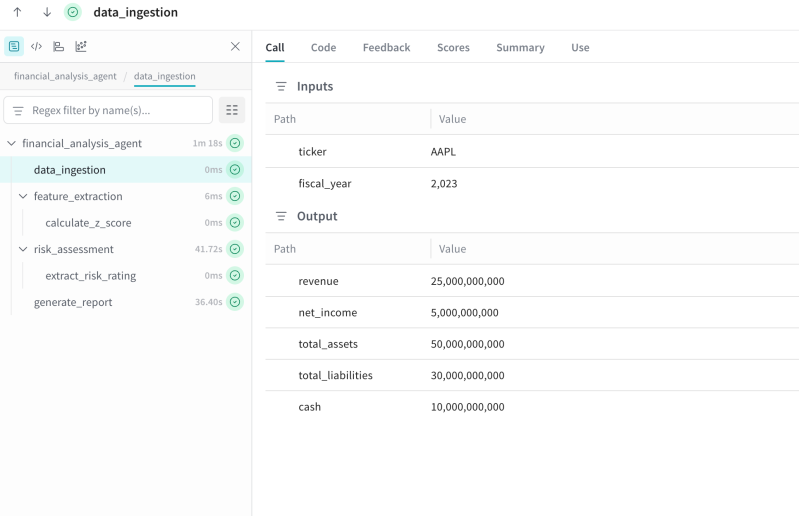
Effective agent monitoring requires two essential components: dashboards showing aggregate behavior across all agents, and detailed traces explaining specific failures. Most platforms provide only one. Here’s what having both looks like in practice.
What is Agent Observability?
Agent observability provides complete visibility into AI agent operations: model invocations, tool selections, decision sequences, handoffs, token consumption, and associated costs.
Traditional application monitoring focuses on requests, errors, and response times. This works adequately for stateless HTTP services where requests are independent.