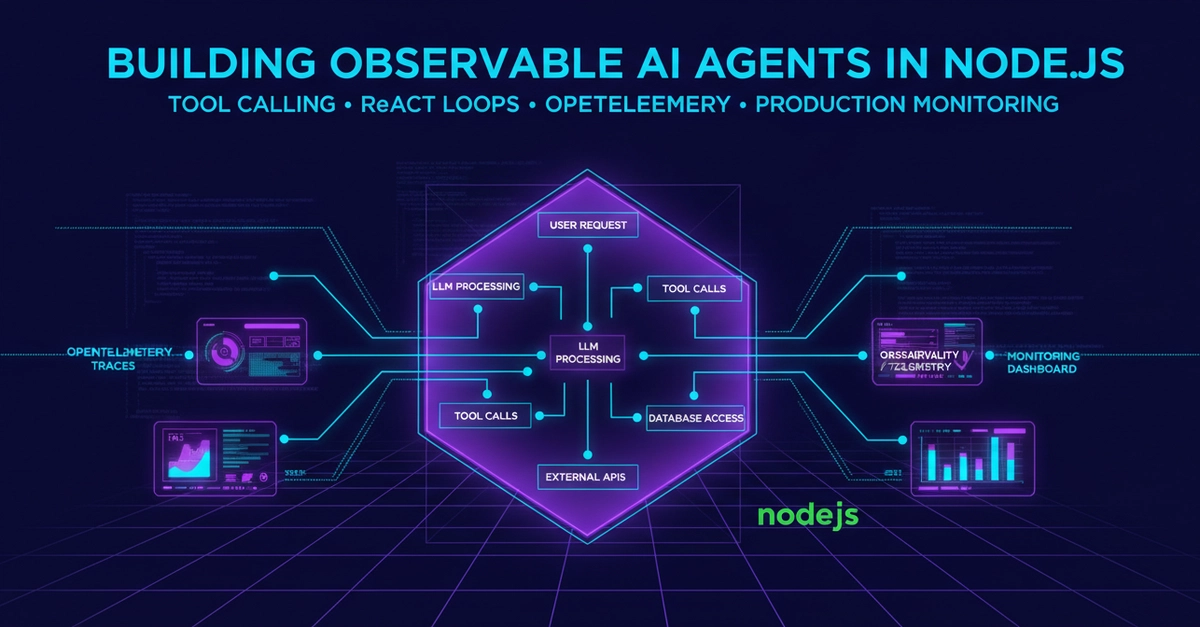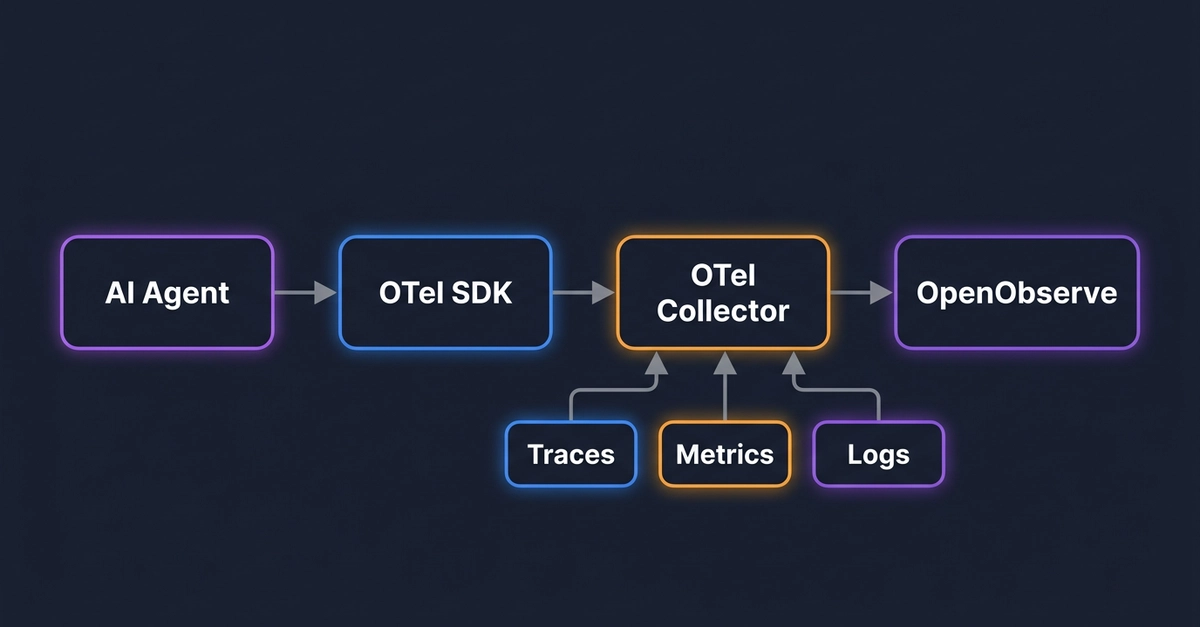
Monitoring AI agents in production requires distributed tracing: a single user request fans out into 10 or more internal operations, and logs alone cannot show you which step is slow, failing, or burning your token budget.
OpenTelemetry's gen_ai.* semantic conventions give you standardized span attributes for LLM calls, tool invocations, and agent steps. Some are stable today; others are still experimental.
Auto-instrumentation libraries (OpenLLMetry, OpenInference, OpenLIT) cover most agent frameworks with two to three lines of initialization code. You do not change your agent code.
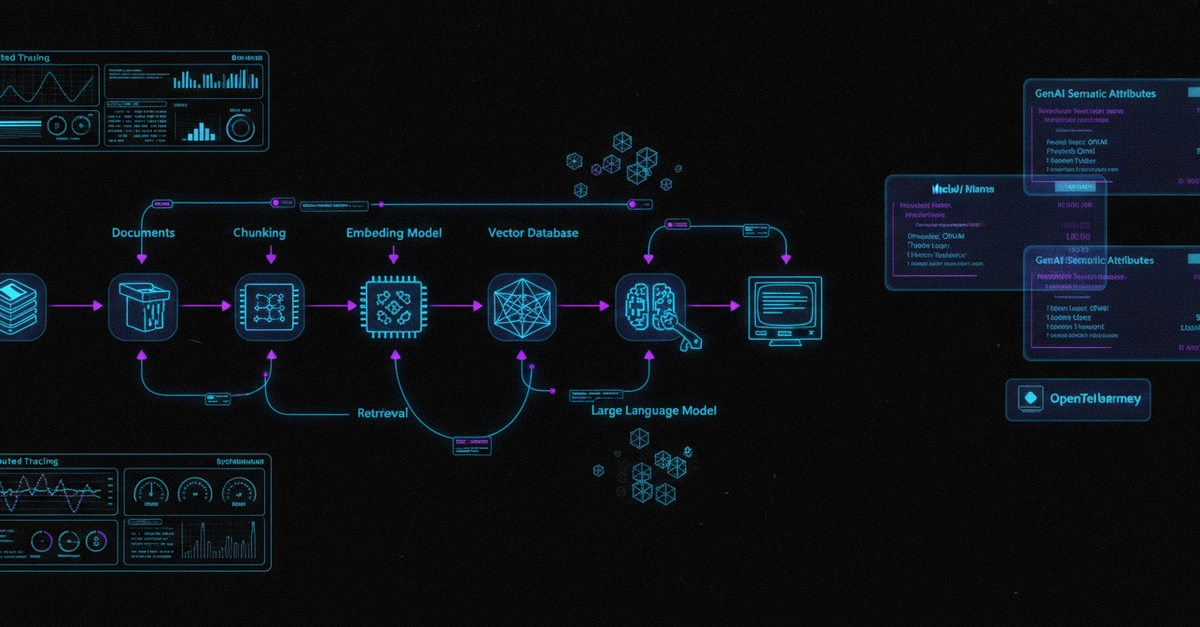
Traces ship to OpenObserve over OTLP. From there you get SQL-queryable trace data, token usage dashboards, cost attribution by agent and model, and alerting on latency and cost anomalies.
OpenObserve also exposes an MCP server. You can query your live agent traces from a Claude or GPT session without opening a dashboard.