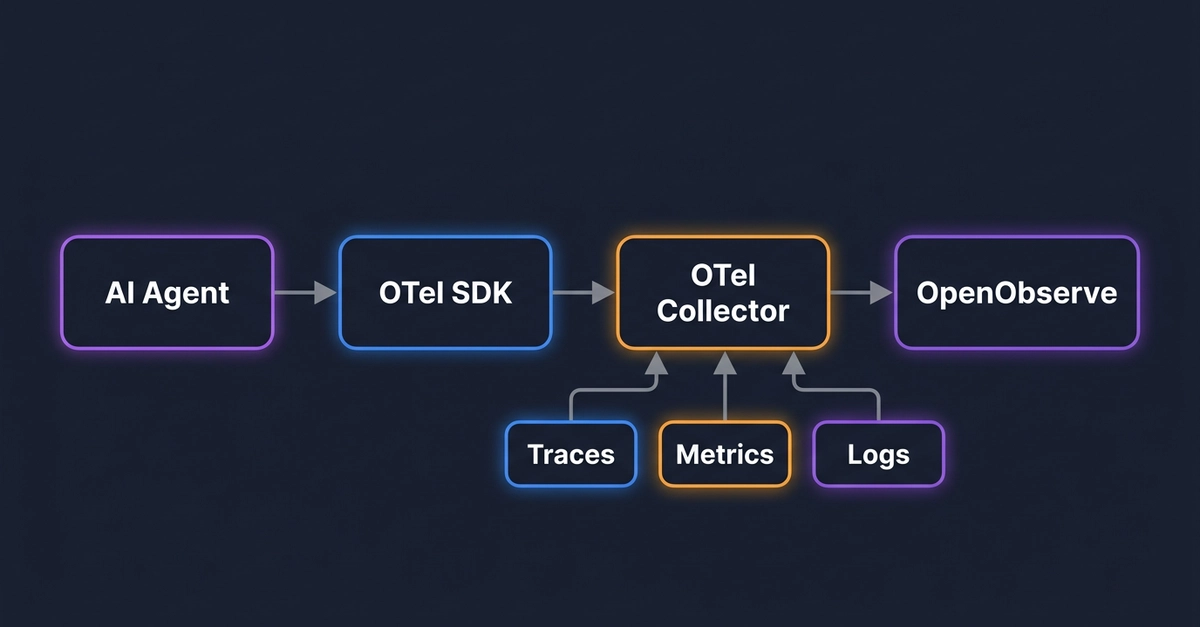
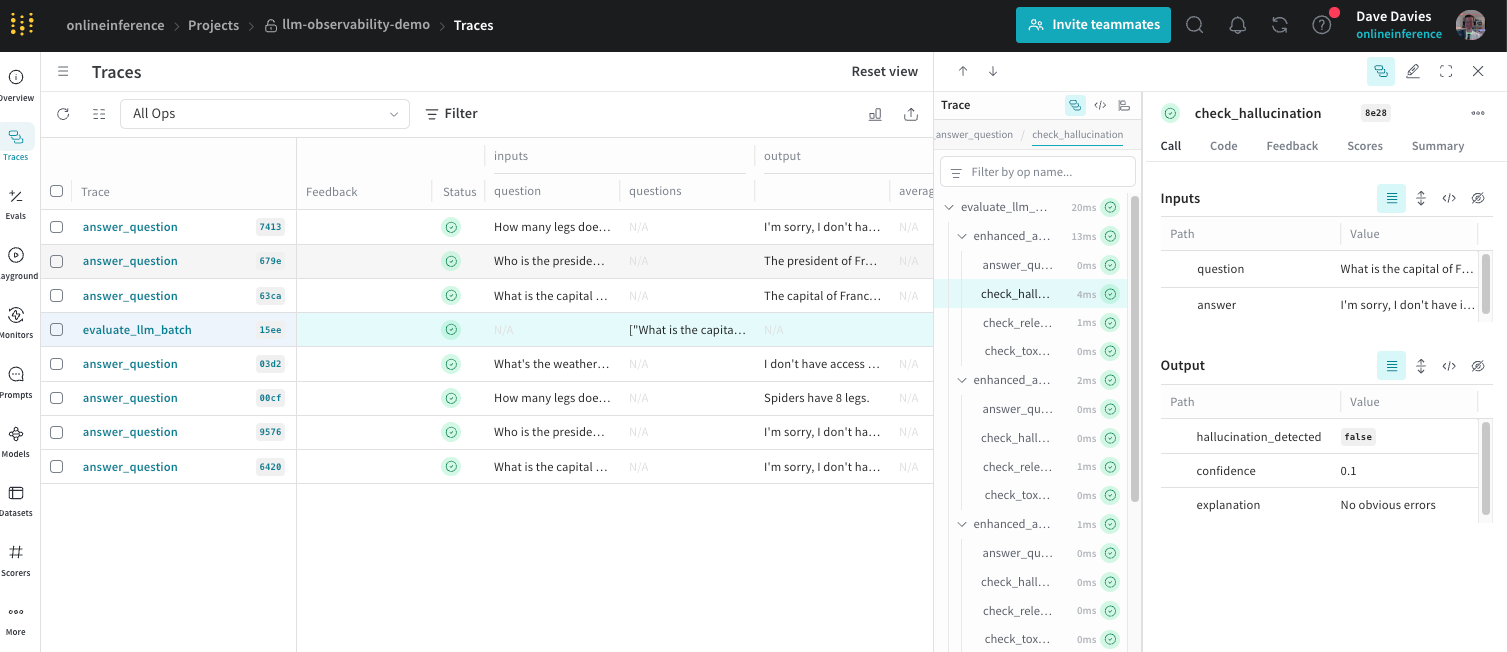
Agents, LLMs, vector stores, custom logic—visibility can’t stop at the model call.Get the context you need to debug failures, optimize performance, and keep AI features reliable. Tolerated by 4 million developers AnthropicCursorGitHubVercelMicrosoftBoltFactory AICognitionPineconeElevenLabsGleanHarveyMistralReplit Full LLM Observability See everything on one pane of glass Track all agent runs, error rates, LLM calls, tokens used, and tool executions. Monitor traffic patterns and duration metrics across your AI-powered features. See Docs Track Model Costs & Tokens Monitor spending across models. Compare costs across different models. See token usage breakdown by model, track input vs output tokens, and identify expensive operations. See Docs Monitor tool execution Track agent tool calls and errors. See which tools your agents call, their error rates, average duration, and P95 latency. Identify slow or failing tool executions before they impact users. Learn About Tracing Deep Trace Analysis Debug with full context. Dive into individual requests with full prompt and response context. See AI spans with agent invocations, tool executions, token counts, costs, and timing. Learn More Getting started with Sentry is simple We support every technology (except the ones we don't). Get started with just a few lines of code.
AI Observability: LLM Cost, Latency, and Errors
Monitor your AI agent’s reliability, speed, and cost with Sentry. Get alerts for LLM errors, latency spikes, and budget overruns before users notice
253 words~1 min read