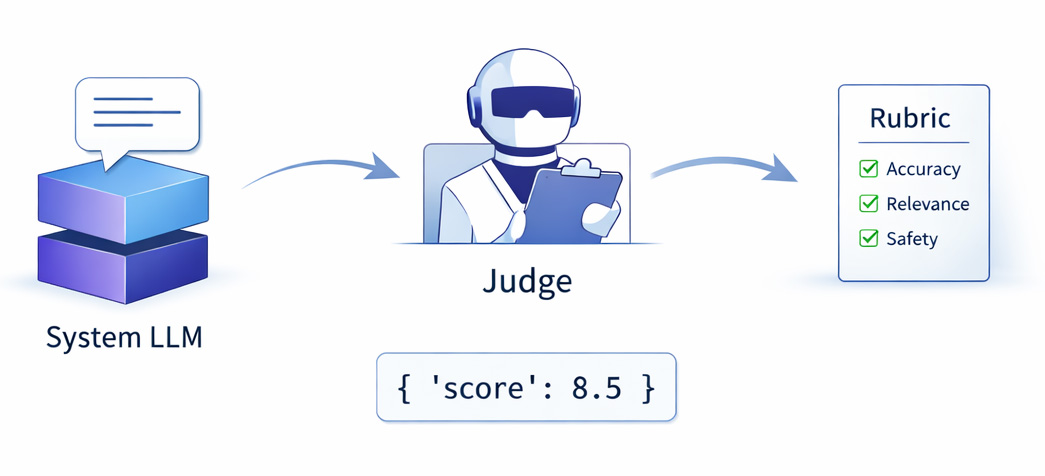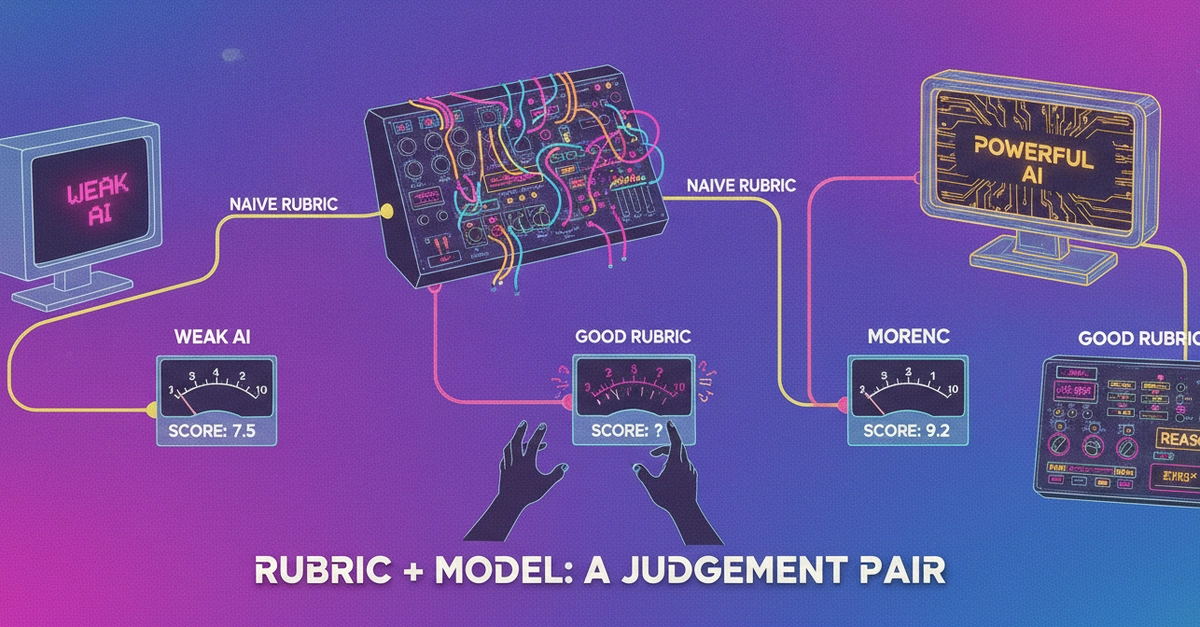
In Part 2 I built the laziest possible LLM judge — a tiny model (Qwen2.5-1.5B) and a one-line rubric — and it agreed with human votes only ~43% of the time, crammed every score into a 7–8 band, and tied a third of the comparisons humans had no trouble separating.
Two things were wrong with that judge, and people usually fix only one:
The model was too small.
The rubric told it almost nothing.
I fixed each independently and measured the effect. The result wasn't the tidy "write a better rubric, it's free" story I expected — it was more interesting than that.