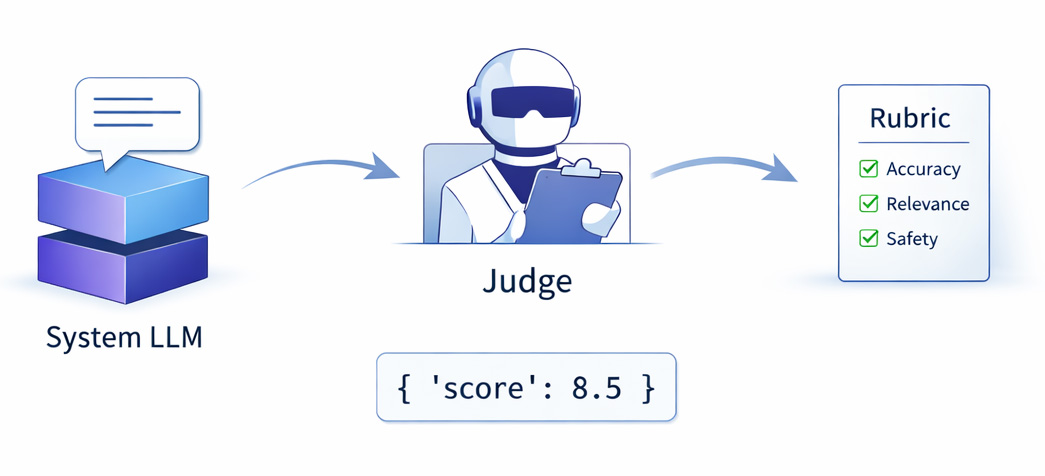
LLM-as-judge has become the dominant pattern for evaluating language model outputs. Tools like Promptfoo, Braintrust, LangSmith all converge on the same architecture: send your prompt to your model, send the output to a different model with a rubric, take the second model's score as the quality signal.
This works. It's also expensive (judge tokens cost real money), slow (extra API roundtrip), variance-prone (the same eval gets different scores across runs), and architecturally a bit circular (using an LLM to evaluate an LLM trained on overlapping data distributions). The single signal becomes a bottleneck for trust.
So I built an eval module that has two independent signals instead of one.
What the tool does
Side-by-side blind comparison. Two agents answer the same prompt. One runs raw, the other can optionally have a cognitive harness wired in as a tool call. A separate blind judge model scores both responses, sees only A and B labels with no knowledge of which is which. Standard setup so far.