In Part 1 the model's job was to pick one of 77 labels, so I could check it with ==. But most real LLM output isn't like that — it's a paragraph, a summary, a support reply. There's no label to compare against.
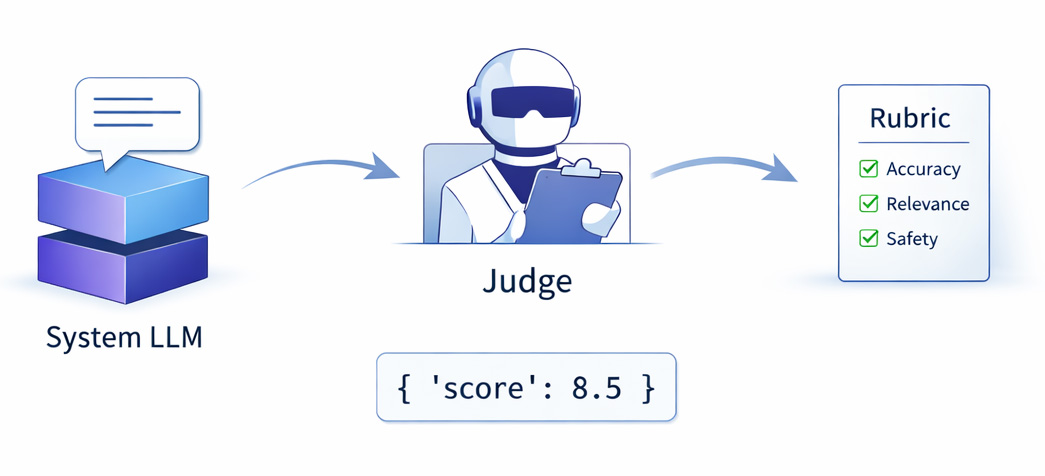
So people reach for the obvious move: use an LLM to grade the LLM. Show it a question and an answer, ask "how good is this, 1–10?", trust the number. It works shockingly well... right up until it doesn't, in ways that don't show up unless you go looking.
I built that judge from scratch and checked it against a dataset that comes with real human votes: the LMSYS Chatbot Arena conversations (via the ungated mirror agie-ai/lmsys-chatbot_arena_conversations, so this runs cold on Kaggle). Each row is a real user prompt, two chatbot answers, and a human verdict for which was better.
The judge is one prompt and a regex
JUDGE_RUBRIC = (